[System design interview] CHƯƠNG 9: THIẾT KẾ WEB CRAWLER

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
CHƯƠNG 9: THIẾT KẾ WEB CRAWLER
Trong chương này, chúng ta sẽ tập trung vào thiết kế Web Crawler: một câu hỏi phỏng vấn thiết kế hệ thống thú vị và kinh điển.
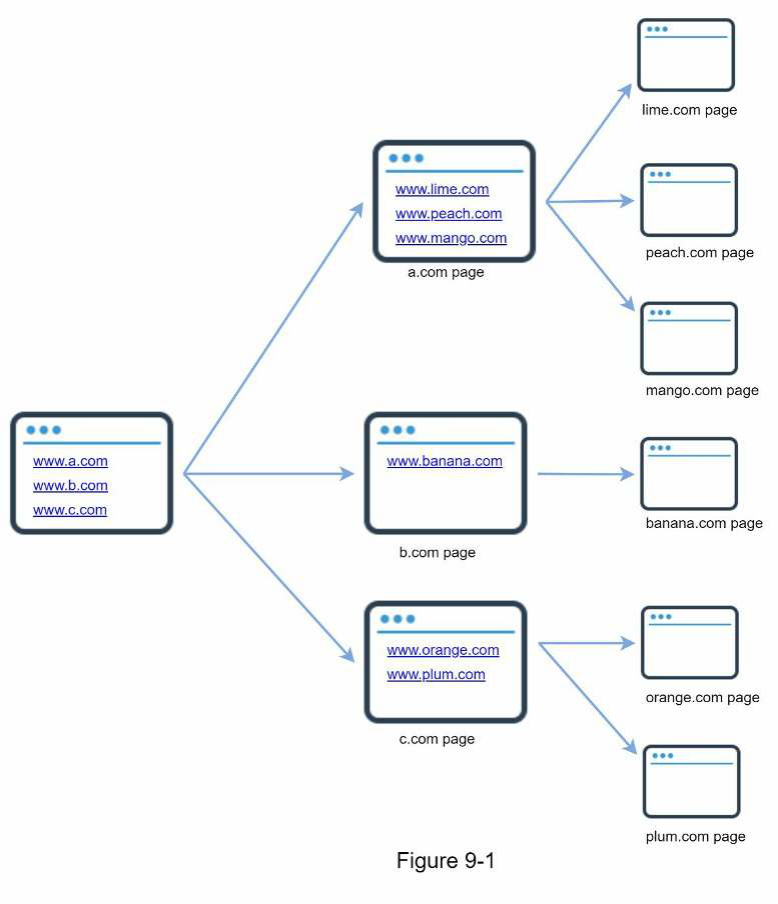
Web Crawler còn được gọi là robot hoặc spider. Nó được các công cụ tìm kiếm sử dụng rộng rãi để khám phá nội dung mới hoặc đã cập nhật trên web. Nội dung có thể là một trang web, hình ảnh, video, tệp PDF, v.v. Một Web Crawler bắt đầu bằng cách thu thập một vài trang web, sau đó theo các liên kết trên những trang đó để thu thập nội dung mới. Hình 9-1 minh họa một ví dụ trực quan về quá trình crawl.
Một crawler được sử dụng cho nhiều mục đích:
-
Lập chỉ mục công cụ tìm kiếm (Search engine indexing): Đây là trường hợp sử dụng phổ biến nhất. Một crawler thu thập các trang web để tạo chỉ mục cục bộ cho các công cụ tìm kiếm. Ví dụ, Googlebot là Web Crawler đằng sau công cụ tìm kiếm Google.
-
Lưu trữ web (Web archiving): Đây là quá trình thu thập thông tin từ web để bảo quản dữ liệu cho các mục đích sử dụng trong tương lai. Chẳng hạn, nhiều thư viện quốc gia vận hành các crawler để lưu trữ các trang web. Các ví dụ đáng chú ý là Thư viện Quốc hội Hoa Kỳ [1] và kho lưu trữ web của EU [2].
-
Khai thác web (Web mining): Sự phát triển bùng nổ của web mang đến cơ hội chưa từng có cho
 data mining. Khai thác web giúp khám phá kiến thức hữu ích từ internet. Ví dụ, các công ty tài chính hàng đầu sử dụng các crawler để tải xuống các cuộc họp cổ đông và báo cáo thường niên nhằm tìm hiểu các sáng kiến chính của công ty.
data mining. Khai thác web giúp khám phá kiến thức hữu ích từ internet. Ví dụ, các công ty tài chính hàng đầu sử dụng các crawler để tải xuống các cuộc họp cổ đông và báo cáo thường niên nhằm tìm hiểu các sáng kiến chính của công ty.
- Giám sát web (Web monitoring): Các crawler giúp giám sát các hành vi vi phạm bản quyền và nhãn hiệu trên Internet. Ví dụ, Digimarc [3] sử dụng các crawler để phát hiện các tác phẩm và báo cáo bị sao chép lậu.
Độ phức tạp của việc phát triển một Web Crawler phụ thuộc vào quy mô mà chúng ta dự định hỗ trợ. Nó có thể là một dự án nhỏ ở trường, chỉ mất vài giờ để hoàn thành, hoặc một dự án khổng lồ đòi hỏi sự cải tiến liên tục từ một đội ngũ kỹ sư chuyên trách. Do đó, chúng ta sẽ cùng tìm hiểu về quy mô và các tính năng cần hỗ trợ dưới đây.
Bước 1 - Hiểu vấn đề và xác định phạm vi thiết kế
Thuật toán cơ bản của một Web Crawler rất đơn giản:
- Với một tập hợp các URL, tải xuống tất cả các trang web được địa chỉ bởi các URL đó.
- Trích xuất các URL từ những trang web này.
- Thêm các URL mới vào danh sách các URL cần tải xuống. Lặp lại 3 bước này.
Liệu một Web Crawler có thực sự hoạt động đơn giản như thuật toán cơ bản này không? Không hẳn. Thiết kế một Web Crawler có khả năng mở rộng (scalable) lớn là một nhiệm vụ cực kỳ phức tạp. Không có khả năng ai đó có thể thiết kế một Web Crawler khổng lồ trong thời gian phỏng vấn. Trước khi đi sâu vào thiết kế, chúng ta phải đặt câu hỏi để hiểu các yêu cầu và xác định phạm vi thiết kế:
Ứng viên : Mục đích chính của crawler là gì? Nó được sử dụng để lập chỉ mục công cụ tìm kiếm, khai thác dữ liệu hay mục đích nào khác? Người phỏng vấn : Lập chỉ mục công cụ tìm kiếm.
Ứng viên : Web Crawler thu thập bao nhiêu trang web mỗi tháng? Người phỏng vấn : 1 tỷ trang.
Ứng viên : Những loại nội dung nào được bao gồm? Chỉ HTML hay các loại nội dung khác như PDF và hình ảnh nữa? Người phỏng vấn : Chỉ HTML.
Ứng viên : Chúng ta có nên xem xét các trang web mới được thêm hoặc chỉnh sửa không? Người phỏng vấn : Có, chúng ta nên xem xét các trang web mới được thêm hoặc chỉnh sửa.
Ứng viên : Chúng ta có cần lưu trữ các trang HTML được crawl từ web không? Người phỏng vấn : Có, tối đa 5 năm.
Ứng viên : Chúng ta xử lý các trang web có nội dung trùng lặp như thế nào? Người phỏng vấn : Các trang có nội dung trùng lặp nên được bỏ qua.
Trên đây là một số câu hỏi mẫu mà bạn có thể hỏi người phỏng vấn. Điều quan trọng là phải hiểu các yêu cầu và làm rõ những điểm mơ hồ. Ngay cả khi bạn được yêu cầu thiết kế một sản phẩm đơn giản như Web Crawler, bạn và người phỏng vấn có thể không có cùng những giả định.
Bên cạnh các chức năng cần làm rõ với người phỏng vấn, điều quan trọng là phải ghi lại các đặc điểm sau của một Web Crawler tốt:
-
Khả năng mở rộng (Scalability): Web rất lớn. Có hàng tỷ trang web ngoài kia. Việc Web crawling cần phải cực kỳ hiệu quả bằng cách sử dụng song song hóa (parallelization).
-
Tính mạnh mẽ (Robustness): Web đầy rẫy cạm bẫy. HTML xấu, máy chủ không phản hồi, sự cố, liên kết độc hại, v.v., đều rất phổ biến. Crawler phải xử lý tất cả những trường hợp biên (edge cases) đó.
-
Tính lịch sự (Politeness): Crawler không nên gửi quá nhiều yêu cầu đến một trang web trong một khoảng thời gian ngắn.
-
Khả năng mở rộng (Extensibility): Hệ thống phải linh hoạt để chỉ cần thay đổi tối thiểu khi hỗ trợ các loại nội dung mới. Ví dụ, nếu chúng ta muốn crawl các tệp hình ảnh trong tương lai, chúng ta không cần phải thiết kế lại toàn bộ hệ thống.
Ước tính nhanh (Back of the envelope estimation)
Các ước tính sau đây dựa trên nhiều giả định, và điều quan trọng là phải trao đổi với người phỏng vấn để đảm bảo cả hai bên có cùng quan điểm.
-
Giả sử 1 tỷ trang web được tải xuống mỗi tháng.
-
QPS: 1.000.000.000 / 30 ngày / 24 giờ / 3600 giây = ~400 trang mỗi giây.
-
QPS cao điểm (Peak QPS) = 2 * QPS = 800.
-
Giả sử kích thước trang web trung bình là 500KB.
-
1 tỷ trang x 500KB = 500 TB dung lượng lưu trữ mỗi tháng. Nếu bạn chưa rõ về các đơn vị lưu trữ kỹ thuật số, hãy xem lại phần “Lũy thừa của 2” trong Chương 2.
-
Giả sử dữ liệu được lưu trữ trong 5 năm, 500 TB * 12 tháng * 5 năm = 30 PB. Cần 30 PB dung lượng lưu trữ để chứa nội dung trong 5 năm.
Bước 2 - Đề xuất thiết kế cấp cao và nhận được sự đồng thuận
Khi các yêu cầu đã rõ ràng, chúng ta sẽ chuyển sang thiết kế cấp cao. Lấy cảm hứng từ các nghiên cứu trước đây về thu thập dữ liệu web (tiếng Anh: web crawling) [4] [5], chúng ta đề xuất một thiết kế cấp cao như minh họa trong Hình 9-2.
Đầu tiên, chúng ta sẽ tìm hiểu từng thành phần thiết kế để nắm rõ chức năng của chúng. Sau đó, chúng ta sẽ xem xét quy trình làm việc của trình thu thập dữ liệu (tiếng Anh: crawler) từng bước một.
Seed URL Một web crawler sử dụng các seed URL (tiếng Anh: seed URLs) làm điểm khởi đầu cho quá trình thu thập dữ liệu. Ví dụ, để thu thập tất cả các trang web từ một trang web của trường đại học, một cách trực quan để chọn seed URL là sử dụng tên miền của trường đại học đó.
Để thu thập toàn bộ web, chúng ta cần sáng tạo trong việc lựa chọn seed URL. Một seed URL tốt đóng vai trò là điểm khởi đầu hiệu quả để crawler có thể tận dụng và duyệt qua càng nhiều liên kết càng tốt. Chiến lược chung là chia toàn bộ không gian URL thành các phần nhỏ hơn. Cách tiếp cận đầu tiên được đề xuất dựa trên tính cục bộ (tiếng Anh: locality) vì các quốc gia khác nhau có thể có các trang web phổ biến khác nhau. Một cách khác là chọn seed URL dựa trên chủ đề; ví dụ, chúng ta có thể chia không gian URL thành mua sắm, thể thao, chăm sóc sức khỏe, v.v. Việc lựa chọn seed URL là một câu hỏi mở. Chúng ta không cần đưa ra câu trả lời hoàn hảo. Hãy cứ trình bày suy nghĩ của mình.
URL Frontier Hầu hết các web crawler hiện đại chia trạng thái thu thập dữ liệu thành hai loại: cần tải xuống và đã tải xuống. Thành phần lưu trữ các URL cần tải xuống được gọi là URL Frontier. Chúng ta có thể coi đây là một hàng đợi First-in-First-out (FIFO). Để biết thông tin chi tiết về URL Frontier, hãy tham khảo phần đi sâu phân tích.
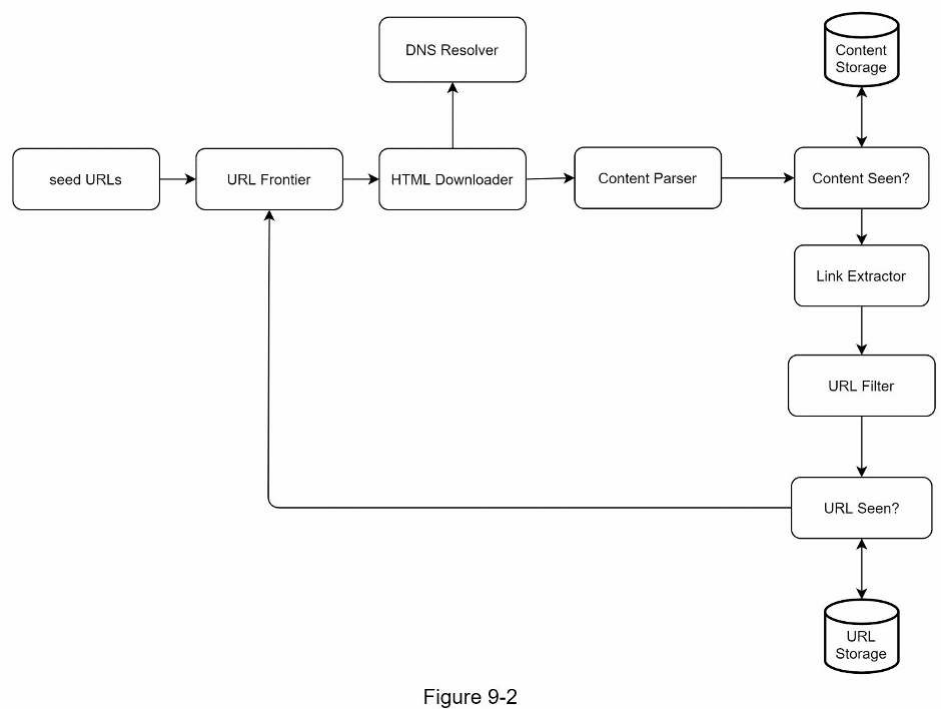 HTML Downloader
HTML Downloader tải các trang web từ internet. Các URL này được cung cấp bởi URL Frontier.
HTML Downloader
HTML Downloader tải các trang web từ internet. Các URL này được cung cấp bởi URL Frontier.
DNS Resolver Để tải xuống một trang web, một URL phải được dịch sang địa chỉ IP. HTML Downloader gọi DNS Resolver để lấy địa chỉ IP tương ứng cho URL. Ví dụ, URL www.wikipedia.org được chuyển đổi thành địa chỉ IP 198.35.26.96 tính đến ngày 3/5/2019.
Content Parser Sau khi một trang web được tải xuống, nó phải được phân tích cú pháp (tiếng Anh: parsed) và xác thực (tiếng Anh: validated) vì các trang web bị lỗi định dạng (tiếng Anh: malformed) có thể gây ra vấn đề và lãng phí không gian lưu trữ. Việc triển khai một content parser trong một máy chủ thu thập dữ liệu sẽ làm chậm quá trình thu thập dữ liệu. Do đó, content parser là một thành phần riêng biệt.
Content Seen? Nghiên cứu trực tuyến [6] cho thấy 29% các trang web có nội dung trùng lặp, điều này có thể khiến cùng một nội dung được lưu trữ nhiều lần. Chúng ta giới thiệu cấu trúc dữ liệu (tiếng Anh: data structure) “Content Seen?” để loại bỏ sự dư thừa dữ liệu và rút ngắn thời gian xử lý. Nó giúp phát hiện nội dung mới đã được lưu trữ trước đó trong hệ thống. Để so sánh hai tài liệu HTML, chúng ta có thể so sánh chúng từng ký tự một. Tuy nhiên, phương pháp này chậm và tốn thời gian, đặc biệt khi liên quan đến hàng tỷ trang web. Một cách hiệu quả để thực hiện nhiệm vụ này là so sánh giá trị băm (tiếng Anh: hash values) của hai trang web [7].
Content Storage Đây là một hệ thống lưu trữ nội dung HTML. Việc lựa chọn hệ thống lưu trữ phụ thuộc vào các yếu tố như loại dữ liệu, kích thước dữ liệu, tần suất truy cập, vòng đời, v.v. Cả đĩa cứng và bộ nhớ đều được sử dụng.
-
Hầu hết nội dung được lưu trữ trên đĩa cứng vì tập dữ liệu quá lớn để vừa trong bộ nhớ.
-
Nội dung phổ biến được giữ trong bộ nhớ để giảm độ trễ (tiếng Anh: latency).
URL Extractor URL Extractor phân tích cú pháp và trích xuất các liên kết từ các trang HTML. Hình 9-3 minh họa một ví dụ về quy trình trích xuất liên kết. Các đường dẫn tương đối (tiếng Anh: relative paths) được chuyển đổi thành URL tuyệt đối (tiếng Anh: absolute URLs) bằng cách thêm tiền tố “https://en.wikipedia.org”.

URL Filter URL Filter loại trừ các loại nội dung, phần mở rộng tệp, liên kết lỗi và các URL trong các trang web bị "danh sách đen" (tiếng Anh: blacklisted).
URL Seen? “URL Seen?” là một cấu trúc dữ liệu theo dõi các URL đã được truy cập trước đó hoặc đã có trong Frontier. “URL Seen?” giúp tránh việc thêm cùng một URL nhiều lần vì điều này có thể làm tăng tải máy chủ và gây ra các vòng lặp vô hạn (tiếng Anh: infinite loops) tiềm ẩn.
Bloom filter (tiếng Anh: Bloom filter) và hash table (tiếng Anh: hash table) là các kỹ thuật phổ biến để triển khai thành phần “URL Seen?”. Chúng ta sẽ không đi sâu vào chi tiết triển khai của bloom filter và hash table ở đây. Để biết thêm thông tin, hãy tham khảo các tài liệu tham khảo [4] [8].
URL Storage URL Storage lưu trữ các URL đã được truy cập.
Cho đến nay, chúng ta đã thảo luận về từng thành phần của hệ thống. Tiếp theo, chúng ta sẽ kết hợp chúng lại để giải thích quy trình làm việc.
Quy trình làm việc của Web crawler Để giải thích quy trình làm việc từng bước một rõ ràng hơn, các số thứ tự được thêm vào sơ đồ thiết kế như minh họa trong Hình 9-4.
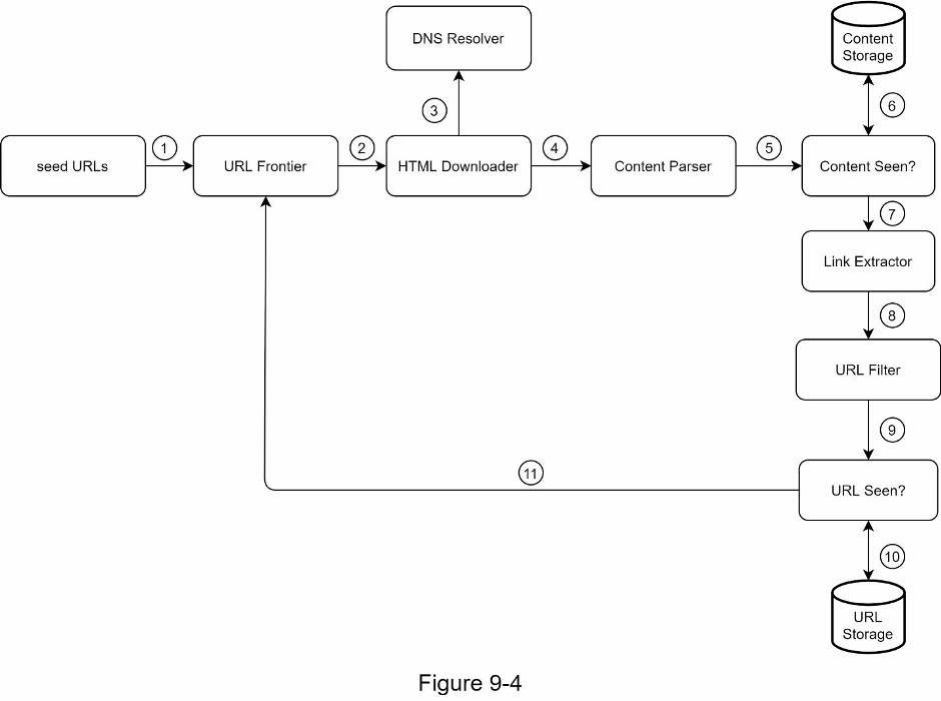
Bước 1: Thêm seed URL vào URL Frontier. Bước 2: HTML Downloader lấy một danh sách các URL từ URL Frontier. Bước 3: HTML Downloader lấy địa chỉ IP của các URL từ DNS resolver và bắt đầu tải xuống. Bước 4: Content Parser phân tích cú pháp các trang HTML và kiểm tra xem các trang có bị lỗi định dạng hay không. Bước 5: Sau khi nội dung được phân tích cú pháp và xác thực, nó được chuyển đến thành phần “Content Seen?”. Bước 6: Thành phần “Content Seen” kiểm tra xem một trang HTML đã có trong bộ nhớ hay chưa.
-
Nếu nó đã có trong bộ nhớ, điều này có nghĩa là cùng một nội dung ở một URL khác đã được xử lý. Trong trường hợp này, trang HTML sẽ bị loại bỏ.
-
Nếu nó chưa có trong bộ nhớ, hệ thống chưa xử lý cùng một nội dung trước đó. Nội dung được chuyển đến Link Extractor. Bước 7: Link extractor trích xuất các liên kết từ các trang HTML. Bước 8: Các liên kết đã trích xuất được chuyển đến URL filter. Bước 9: Sau khi các liên kết được lọc, chúng được chuyển đến thành phần “URL Seen?”. Bước 10: Thành phần “URL Seen” kiểm tra xem một URL đã có trong bộ nhớ hay chưa; nếu có, nó đã được xử lý trước đó và không cần thực hiện thêm hành động nào. Bước 11: Nếu một URL chưa được xử lý trước đó, nó sẽ được thêm vào URL Frontier.
Bước 3 - Đi sâu vào thiết kế
Cho đến nay, chúng ta đã thảo luận về thiết kế cấp cao. Tiếp theo, chúng ta sẽ đi sâu vào các thành phần và kỹ thuật xây dựng quan trọng nhất:
-
Depth-first search (DFS) (tiếng Anh: Depth-first search) so với Breadth-first search (BFS) (tiếng Anh: Breadth-first search)
-
URL Frontier
-
HTML Downloader
-
Tính mạnh mẽ (tiếng Anh: Robustness)
-
Khả năng mở rộng (tiếng Anh: Extensibility)
-
Phát hiện và tránh nội dung có vấn đề
DFS so với BFS
Chúng ta có thể hình dung web như một đồ thị có hướng (tiếng Anh: directed graph) trong đó các trang web đóng vai trò là các nút (tiếng Anh: nodes) và các siêu liên kết (hyperlinks - URL) là các cạnh (tiếng Anh: edges). Quá trình thu thập dữ liệu có thể được xem là việc duyệt qua một đồ thị có hướng từ một trang web này sang các trang web khác. Hai thuật toán duyệt đồ thị phổ biến là DFS và BFS. Tuy nhiên, DFS thường không phải là lựa chọn tốt vì độ sâu của DFS có thể rất lớn.
BFS thường được sử dụng bởi các web crawler và được triển khai bằng một hàng đợi First-in-First-out (FIFO). Trong một hàng đợi FIFO, các URL được lấy ra theo thứ tự chúng được thêm vào. Tuy nhiên, việc triển khai này có hai vấn đề:
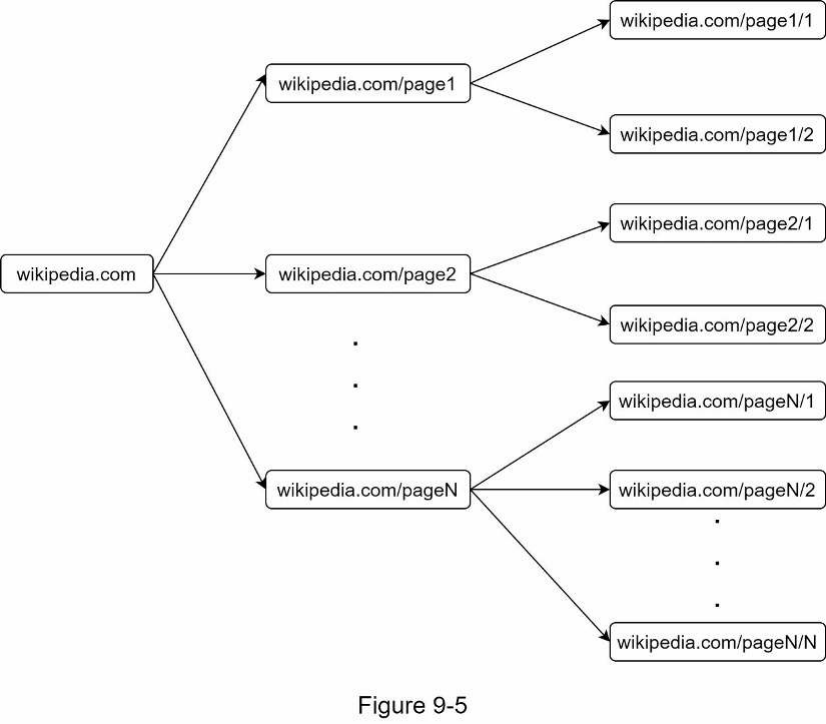
- Hầu hết các liên kết từ cùng một trang web đều liên kết trở lại cùng một máy chủ (tiếng Anh: host). Trong Hình 9-5, tất cả các liên kết trong wikipedia.com là các liên kết nội bộ (tiếng Anh: internal links), khiến crawler bận rộn xử lý các URL từ cùng một máy chủ (wikipedia.com). Khi crawler cố gắng tải xuống các trang web song song, các máy chủ của Wikipedia sẽ bị tràn ngập yêu cầu. Điều này được coi là "thiếu lịch sự".
- BFS tiêu chuẩn không xem xét đến mức độ ưu tiên của một URL. Web rất lớn và không phải trang nào cũng có cùng mức độ chất lượng và tầm quan trọng. Do đó, chúng ta có thể muốn ưu tiên các URL dựa trên thứ hạng trang (tiếng Anh: page ranks), lưu lượng truy cập web (tiếng Anh: web traffic), tần suất cập nhật, v.v.
- BFS tiêu chuẩn không xem xét mức độ ưu tiên của một URL. Web rất rộng lớn và không phải mọi trang đều có cùng mức độ chất lượng và tầm quan trọng. Do đó, chúng ta có thể muốn ưu tiên các URL dựa trên thứ hạng trang, lưu lượng truy cập web, tần suất cập nhật, v.v.
URL frontier
URL frontier giúp giải quyết những vấn đề này. URL frontier là một cấu trúc dữ liệu lưu trữ các URL cần tải xuống. URL frontier là một thành phần quan trọng để đảm bảo tính lịch sự, ưu tiên URL và tính tươi mới. Một số tài liệu đáng chú ý về URL frontier được đề cập trong phần tài liệu tham khảo [5] [9]. Các phát hiện từ những tài liệu này như sau:
Politeness Thông thường, một trình thu thập thông tin web (web crawler) nên tránh gửi quá nhi�ều yêu cầu đến cùng một máy chủ lưu trữ trong một khoảng thời gian ngắn. Việc gửi quá nhiều yêu cầu được coi là "thiếu lịch sự" hoặc thậm chí bị coi là một cuộc tấn công từ chối dịch vụ (DOS). Ví dụ, nếu không có bất kỳ ràng buộc nào, trình thu thập thông tin có thể gửi hàng nghìn yêu cầu mỗi giây đến cùng một trang web. Điều này có thể làm quá tải các máy chủ web.
Ý tưởng chung để thực thi tính lịch sự là tải xuống từng trang một từ cùng một host. Một khoảng trễ có thể được thêm vào giữa hai tác vụ tải
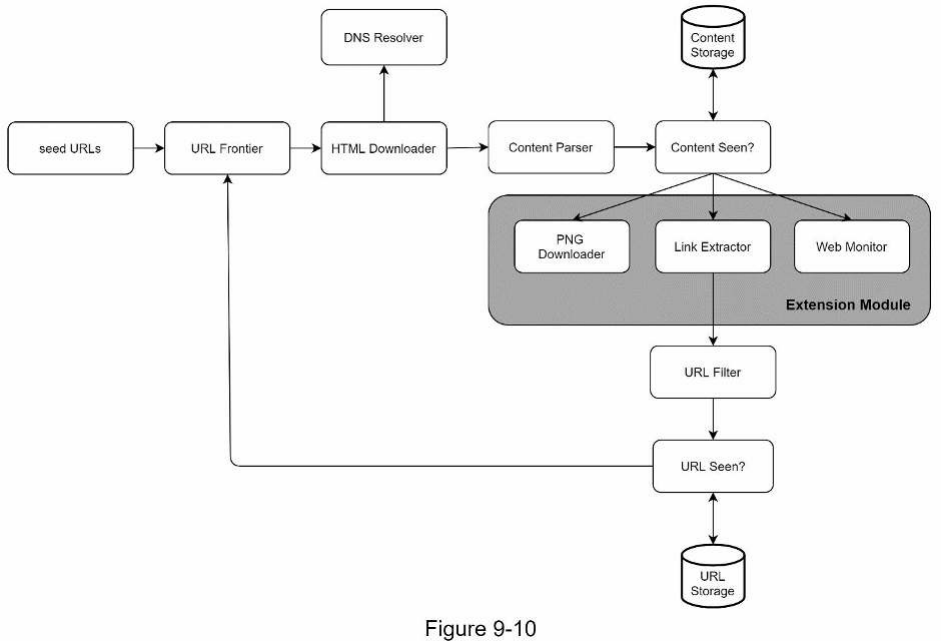
[Context từ đoạn trước]: ...ough to support new content types. The crawler can be extended by plugging in new modules. Figure 9-10 shows how to add new modules.
-
PNG Downloader module is plugged-in to download PNG files.
-
Web Monitor module is added to monitor the web and prevent copyright and trademark infringements.
Phát hiện và tránh nội dung có vấn đề
Phần này thảo luận về việc phát hiện và ngăn chặn nội dung dư thừa, vô nghĩa hoặc có hại.
1. Nội dung dư thừa Như đã thảo luận trước đây, gần 30% các trang web là bản sao. Các hàm băm (hashes) hoặc checksum giúp phát hiện sự trùng lặp [11].
2. Bẫy nhện Bẫy nhện (spider trap) là một trang web khiến trình thu thập dữ liệu (crawler) rơi vào vòng lặp vô hạn. Ví dụ, một cấu trúc thư mục sâu vô hạn có thể được liệt kê như sau: www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/…
Có thể tránh các bẫy nhện như vậy bằng cách đặt độ dài tối đa cho URL. Tuy nhiên, không có giải pháp nào phù hợp cho tất cả các trường hợp để phát hiện bẫy nhện. Các trang web chứa bẫy nhện dễ dàng được xác định nhờ số lượng trang web được phát hiện trên đó lớn bất thường. Khó có thể phát triển các thuật toán tự động để tránh bẫy nhện; tuy nhiên, người dùng có thể tự mình
 xác minh và nhận diện bẫy nhện, sau đó loại trừ các trang web đó khỏi trình thu thập dữ liệu hoặc áp dụng một số bộ lọc URL tùy chỉnh.
xác minh và nhận diện bẫy nhện, sau đó loại trừ các trang web đó khỏi trình thu thập dữ liệu hoặc áp dụng một số bộ lọc URL tùy chỉnh.
3. Nhiễu dữ liệu Một số nội dung có ít hoặc không có giá trị, chẳng hạn như quảng cáo, đoạn mã, URL spam, v.v. Những nội dung đó không hữu ích cho các trình thu thập dữ liệu và nên được loại trừ nếu có thể.
Bước 4 - Tổng kết
Trong chương này, chúng ta đã thảo luận về các đặc điểm của một trình thu thập dữ liệu tốt: khả năng mở rộng (scalability), tính lịch sự (politeness), khả năng mở rộng (extensibility) và tính mạnh mẽ (robustness). Sau đó, chúng ta đã đề xuất một thiết kế và thảo luận về các thành phần chính. Xây dựng một trình thu thập dữ liệu web có khả năng mở rộng không phải là một nhiệm vụ đơn giản vì web cực kỳ rộng lớn và đầy rẫy cạm bẫy. Mặc dù chúng ta đã đề cập đến nhiều chủ đề, nhưng vẫn còn nhiều điểm quan trọng chưa được nhắc đến:
-
Server-side rendering (kết xuất phía máy chủ): Nhiều trang web sử dụng các script như JavaScript, AJAX, v.v. để tạo liên kết ngay lập tức. Nếu chúng ta tải xuống và phân tích cú pháp (parse) các trang web trực tiếp, chúng ta sẽ không thể truy xuất các liên kết được tạo động. Để giải quyết vấn đề này, chúng ta thực hiện server-side rendering (còn gọi là dynamic rendering – kết xuất động) trước khi phân tích cú pháp một trang [12].
-
Lọc bỏ các trang không mong muốn: Với dung lượng lưu trữ và tài nguyên thu thập dữ liệu hữu hạn, một thành phần chống spam sẽ hữu ích trong việc lọc bỏ các trang chất lượng thấp và trang spam [13] [14].
-
Database replication (nhân bản cơ sở dữ liệu) và sharding (phân mảnh): Các kỹ thuật như replication và sharding được sử dụng để cải thiện tính khả dụng (availability), khả năng mở rộng (scalability) và độ tin cậy (reliability) của lớp dữ liệu.
-
Horizontal scaling (mở rộng theo chiều ngang): Đối với việc thu thập dữ liệu quy mô lớn, cần hàng trăm hoặc thậm chí hàng nghìn máy chủ để thực hiện các tác vụ tải xuống. Điều quan trọng là giữ cho các máy chủ không trạng thái (stateless).
-
Availability (tính khả dụng), consistency (tính nhất quán) và reliability (độ tin cậy): Những khái niệm này là cốt lõi cho sự thành công của bất kỳ hệ thống lớn nào. Chúng ta đã thảo luận chi tiết về các khái niệm này trong Chương 1. Hãy ôn lại kiến thức về các chủ đề này.
-
Analytics (phân tích dữ liệu): Thu thập và phân tích dữ liệu là những phần quan trọng của bất kỳ hệ thống nào vì dữ liệu là thành phần then chốt để Fine-tuning.
Chúc mừng bạn đã đi đến đây! Hãy tự thưởng cho mình một lời khen. Làm tốt lắm!
Tài liệu tham khảo
[1] US Library of Congress: https://www.loc.gov/websites/
[2] EU Web Archive: http://data.europa.eu/webarchive
[3] Digimarc: https://www.digimarc.com/products/digimarc-services/piracy-intelligence
[4] Heydon A., Najork M. Mercator: A scalable, extensible web crawler World Wide Web, 2 (4) (1999), pp. 219-229
[5] By Christopher Olston, Marc Najork: Web Crawling. http://infolab.stanford.edu/~olston/publications/crawling_survey.pdf
[6] 29% Of Sites Face Duplicate Content Issues: https://tinyurl.com/y6tmh55y
[7] Rabin M.O., et al. Fingerprinting by random polynomials Center for Research in Computing Techn., Aiken Computation Laboratory, Univ. (1981)
[8] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
[9] Donald J. Patterson, Web Crawling: https://www.ics.uci.edu/~lopes/teaching/cs221W12/slides/Lecture05.pdf
[10] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citation ranking: Bringing order to the web,” Technical Report, Stanford University, 1998.
[11] Burton Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), pages 422--426, July 1970.
[12] Google Dynamic Rendering: https://developers.google.com/search/docs/guides/dynamic-rendering
[13] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on Adversarial Information Retrieval on the Web, 2006.
[14] H.-T. Lee, D. Leonard, X. Wang, and D. Loguinov, “IRLbot: Scaling to 6 billion pages and beyond,” in Proceedings of the 17th International World Wide Web Conference, 2008.
Made by Anh Tu - Share to be share