[System design interview] CHƯƠNG 6: THIẾT KẾ KEY-VALUE STORE

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
CHƯƠNG 6: THIẾT KẾ KEY-VALUE STORE
Một kho dữ liệu key-value (tiếng Anh: key-value store), còn được gọi là cơ sở dữ liệu key-value (tiếng Anh: key-value database), là một cơ sở dữ li��ệu phi quan hệ (tiếng Anh: non-relational database). Mỗi định danh duy nhất (tiếng Anh: unique identifier) được lưu trữ dưới dạng một key với giá trị liên kết của nó. Cặp dữ liệu này được gọi là cặp "key-value".
Trong một cặp key-value, key phải là duy nhất, và giá trị liên kết với key có thể được truy cập thông qua key đó. Các key có thể là văn bản thuần túy (tiếng Anh: plain text) hoặc giá trị băm (tiếng Anh: hashed values). Vì lý do hiệu suất, một key ngắn sẽ hoạt động tốt hơn. Các key trông như thế nào? Dưới đây là một vài ví dụ:
-
Key văn bản thuần túy: “last_logged_in_at”
-
Key băm: 253DDEC4
Giá trị trong một cặp key-value có thể là chuỗi, danh sách, đối tượng, v.v. Giá trị thường được coi là một đối tượng mờ (tiếng Anh: opaque object) trong các kho dữ liệu key-value, chẳng hạn như Amazon Dynamo [1], Memcached [2], Redis [3], v.v.
Dưới đây là một đoạn dữ liệu trong một kho dữ liệu key-value:
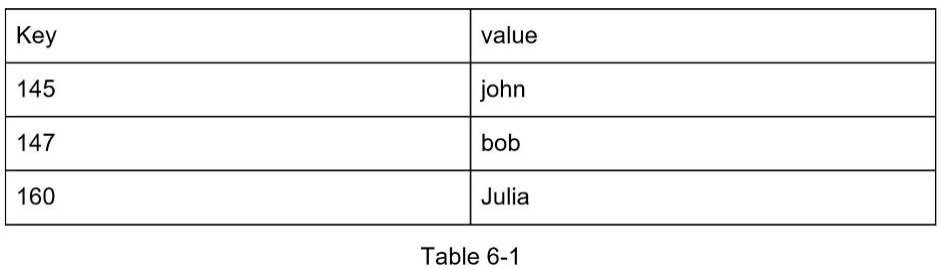
Trong chương này, chúng ta sẽ thiết kế một kho dữ liệu key-value hỗ trợ các thao tác sau:
-
put(key, value) // chèn “value” liên kết với “key”
-
get(key) // lấy “value” liên kết với “key”
Hiểu vấn đề và thiết lập phạm vi thiết kế
Không có thiết kế nào là hoàn hảo. Mỗi thiết kế đạt được một sự cân bằng cụ thể về các đánh đổi giữa việc đọc, ghi và sử dụng bộ nhớ. Một đánh đổi khác phải được thực hiện là giữa Consistency và Availability. Trong chương này, chúng ta thiết kế một kho dữ liệu key-value bao gồm các đặc điểm sau:
-
Kích thước của một cặp key-value nhỏ: dưới 10 KB.
-
Khả năng lưu trữ Big Data.
-
High Availability: Hệ thống phản hồi nhanh chóng, ngay cả khi xảy ra lỗi.
-
High Scalability: Hệ thống có thể được mở rộng để hỗ trợ tập dữ liệu lớn.
-
Automatic Scaling: Việc thêm/xóa máy chủ phải tự động dựa trên lưu lượng truy cập.
-
Tunable Consistency.
-
Low Latency.
Kho dữ liệu key-value trên một máy chủ
Phát triển một kho dữ liệu key-value nằm trên một máy chủ duy nhất là điều dễ dàng. Một cách tiếp cận trực quan là lưu trữ các cặp key-value trong một bảng băm (tiếng Anh: hash table), giữ mọi thứ trong bộ nhớ. Mặc dù truy cập bộ nhớ nhanh, nhưng việc chứa tất cả mọi thứ trong bộ nhớ có thể là không thể do ràng buộc về không gian. Hai tối ưu hóa có thể được thực hiện để chứa nhiều dữ liệu hơn trên một máy chủ duy nhất:
-
Nén dữ liệu (tiếng Anh: Data compression)
-
Chỉ lưu trữ dữ liệu thường xuyên được sử dụng trong bộ nhớ và phần còn lại trên đĩa
Ngay cả với những tối ưu hóa này, một máy chủ duy nhất có thể đạt đến dung lượng của nó rất nhanh chóng. Một kho dữ liệu key-value phân tán (tiếng Anh: distributed key-value store) là cần thiết để hỗ trợ Big Data.
Kho dữ liệu key-value phân tán
Một kho dữ liệu key-value phân tán còn được gọi là bảng băm phân tán (tiếng Anh: distributed hash table), phân tán các cặp key-value trên nhiều máy chủ. Khi thiết kế một hệ thống phân tán, điều quan trọng là phải hiểu CAP theorem (Consistency, Availability, Partition Tolerance).
CAP theorem
CAP theorem phát biểu rằng một hệ thống phân tán không thể đồng thời cung cấp nhiều hơn hai trong ba đảm bảo sau: Consistency, Availability và Partition Tolerance. Hãy cùng thiết lập một vài định nghĩa.
Consistency: Consistency có nghĩa là tất cả các client đều thấy cùng một dữ liệu tại cùng một thời điểm, bất kể chúng kết nối với nút nào.
Availability: Availability có nghĩa là bất kỳ client nào yêu cầu dữ liệu đều nhận được phản hồi ngay cả khi một số nút bị lỗi.
Partition Tolerance: Một phân vùng (tiếng Anh: partition) chỉ ra sự gián đoạn giao tiếp giữa hai nút. Partition Tolerance có nghĩa là hệ thống tiếp tục hoạt động bất chấp các phân vùng mạng.
CAP theorem phát biểu rằng một trong ba thuộc tính phải được đánh đổi để hỗ trợ 2 trong 3 thuộc tính còn lại như thể hiện trong Hình 6-1.
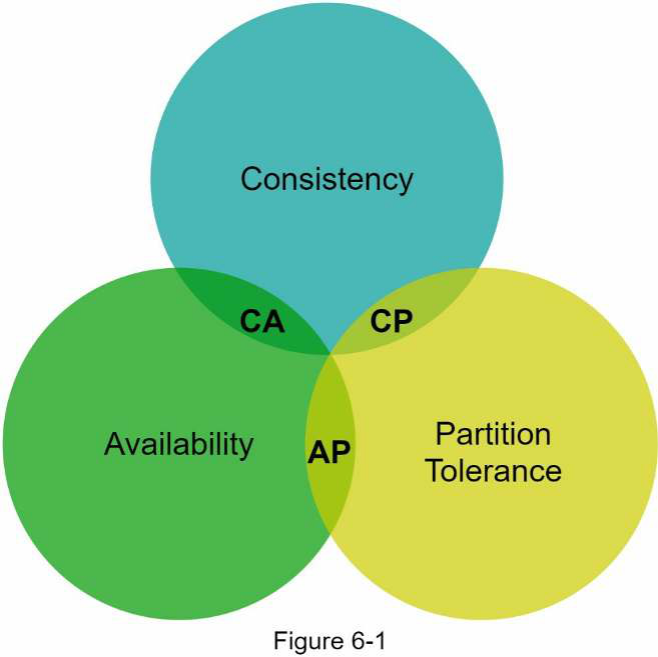
Ngày nay, các kho dữ liệu key-value được phân loại dựa trên hai đặc điểm CAP mà chúng hỗ trợ:
Hệ thống CP (Consistency và Partition Tolerance): Một kho dữ liệu key-value CP hỗ trợ Consistency và Partition Tolerance trong khi đánh đổi Availability.
Hệ thống AP (Availability và Partition Tolerance): Một kho dữ liệu key-value AP hỗ trợ Availability và Partition Tolerance trong khi đánh đổi Consistency.
Hệ thống CA (Consistency và Availability): Một kho dữ liệu key-value CA hỗ trợ Consistency và Availability trong khi đánh đổi Partition Tolerance. Vì lỗi mạng là không thể tránh khỏi, một hệ thống phân tán phải chịu đựng phân vùng mạng. Do đó, một hệ thống CA không thể tồn tại trong các ứng dụng thực tế.
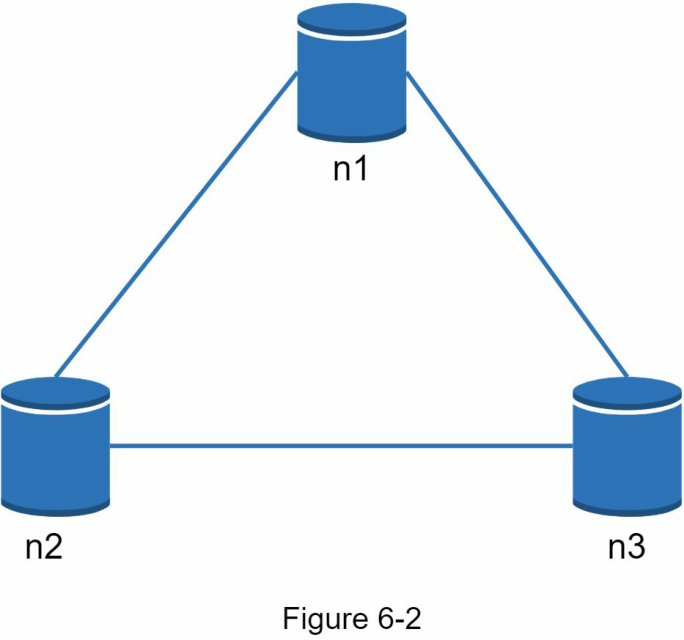
Những gì chúng ta vừa đọc chủ yếu là phần định nghĩa. Để dễ hiểu hơn, hãy cùng xem xét một số ví dụ cụ thể. Trong các hệ thống phân tán, dữ liệu thường được sao chép nhiều lần. Giả sử dữ liệu được sao chép trên ba nút bản sao (tiếng Anh: replica nodes), n1, n2 và n3 như thể hiện trong Hình 6-2.
Tình huống lý tưởng Trong một thế giới lý tưởng, phân vùng mạng không bao giờ xảy ra. Dữ liệu được ghi vào n1 tự động được sao chép sang n2 và n3. Cả Consistency và Availability đều đạt được.
Hệ thống phân tán trong thế giới thực Trong một hệ thống phân tán, các phân vùng là không thể tránh khỏi, và khi một phân vùng xảy ra, chúng ta phải lựa chọn giữa Consistency và Availability. Trong Hình 6-3, n3 bị lỗi và không thể giao tiếp với n1 và n2. Nếu client ghi dữ liệu vào n1 hoặc n2, dữ liệu không thể được truyền tải đến n3. Nếu dữ liệu được ghi vào n3 nhưng chưa được truyền tải đến n1 và n2, thì n1 và n2 sẽ có dữ liệu cũ/lỗi thời (tiếng Anh: stale data).
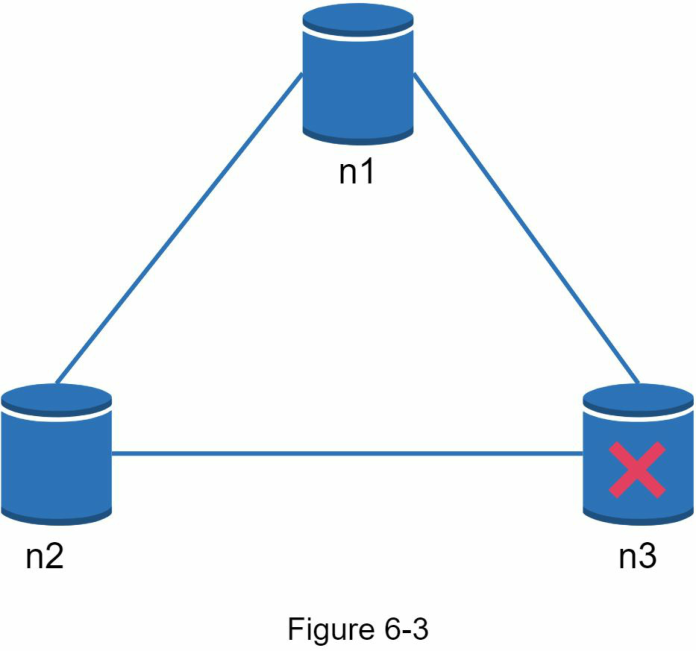
Nếu chúng ta chọn Consistency thay vì Availability (hệ thống CP), chúng ta phải chặn tất cả các thao tác ghi vào n1 và n2 để tránh tính không nhất quán của dữ liệu (tiếng Anh: data inconsistency) giữa ba máy chủ này, điều này khiến hệ thống không khả dụng. Các hệ thống ngân hàng thường có yêu cầu nhất quán cực kỳ cao. Ví dụ, điều quan trọng đối với một hệ thống ngân hàng là phải hiển thị thông tin số dư cập nhật nhất. Nếu tính không nhất quán xảy ra do phân vùng mạng, hệ thống ngân hàng sẽ trả về lỗi trước khi tính không nhất quán được giải quyết.
Tuy nhiên, nếu chúng ta chọn Availability thay vì Consistency (hệ thống AP), hệ thống vẫn tiếp tục chấp nhận các yêu cầu đọc, mặc dù nó có thể trả về dữ liệu cũ/lỗi thời. Đối với các thao tác ghi, n1 và n2 sẽ tiếp tục chấp nhận các thao tác ghi, và dữ liệu sẽ được đồng bộ hóa (tiếng Anh: synced) với n3 khi phân vùng mạng được giải quyết.
Việc lựa chọn các đảm bảo CAP phù hợp với trường hợp sử dụng của bạn là một bước quan trọng trong việc xây dựng một kho dữ liệu key-value phân tán. Bạn có thể thảo luận điều này với người phỏng vấn và thiết kế hệ thống tương ứng.
Các thành phần hệ thống
Trong phần này, chúng ta sẽ thảo luận về các thành phần cốt lõi và kỹ thuật sau đây được sử dụng để xây dựng một kho dữ liệu key-value:
-
Phân vùng dữ liệu (tiếng Anh: Data partition)
-
Sao chép dữ liệu (tiếng Anh: Data replication)
-
Consistency
-
Giải quyết tính không nhất quán (tiếng Anh: Inconsistency resolution)
-
Xử lý lỗi (tiếng Anh: Handling failures)
-
Sơ đồ kiến trúc hệ thống (tiếng Anh: System architecture diagram)
-
Đường dẫn ghi (tiếng Anh: Write path)
-
Đường dẫn đọc (tiếng Anh: Read path)
Nội dung dưới đây phần lớn dựa trên ba hệ thống kho dữ liệu key-value phổ biến: Dynamo [4], Cassandra [5] và BigTable [6].
Phân vùng dữ liệu
Đối với các ứng dụng lớn, việc chứa toàn bộ tập dữ liệu (tiếng Anh: complete data set) trong một máy chủ duy nhất là không khả thi. Cách đơn giản nhất để thực hiện điều này là chia dữ liệu thành các phân vùng nhỏ hơn và lưu trữ chúng trên nhiều máy chủ. Có hai thách thức khi phân vùng dữ liệu:
-
Phân phối dữ liệu đều khắp các máy chủ.
-
Giảm thiểu việc di chuyển dữ liệu khi các nút được thêm hoặc xóa.
Băm nhất quán (tiếng Anh: Consistent hashing) đã được thảo luận trong Chương 5 là một kỹ thuật tuyệt vời để giải quyết những vấn đề này. Hãy cùng xem lại cách băm nhất quán hoạt động ở cấp độ cao.
-
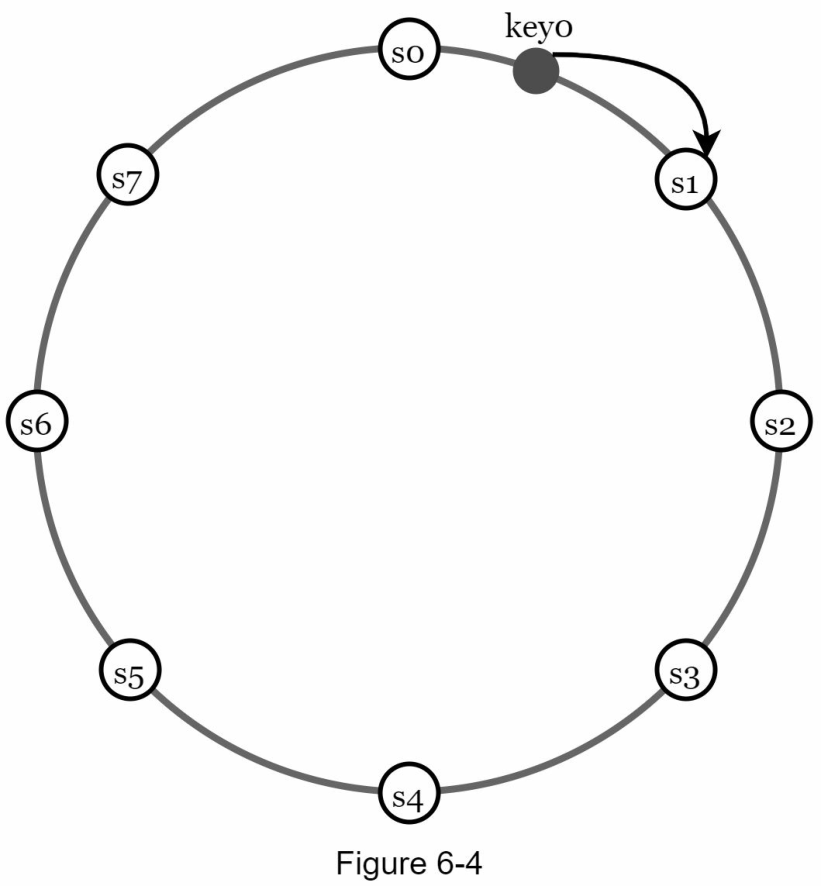
Đầu tiên, các máy chủ được đặt trên một vòng băm (tiếng Anh: hash ring). Trong Hình 6-4, tám máy chủ, được đại diện bởi s0, s1, …, s7, được đặt trên vòng băm.
-
Tiếp theo, một key được băm lên cùng một vòng, và nó được lưu trữ trên máy chủ đầu tiên gặp phải khi di chuyển theo chiều kim đồng hồ. Ví dụ, key0 được lưu trữ trong s1 bằng cách sử dụng logic này.
Sử dụng băm nhất quán để phân vùng dữ liệu có những lợi ích sau:
Tự động mở rộng (tiếng Anh: Automatic scaling): Các máy chủ có thể được thêm và xóa tự động tùy thuộc vào tải.
Tính không đồng nhất (tiếng Anh: Heterogeneity): Số lượng nút ảo (tiếng Anh: virtual nodes) cho một máy chủ tỷ lệ thuận với dung lượng máy chủ. Ví dụ, các máy chủ có dung lượng cao hơn được gán nhiều nút ảo hơn.
tải.
Tính không đồng nhất (Heterogeneity): số lượng node ảo cho một máy chủ tỷ lệ thuận với dung lượng máy chủ. Ví dụ, các máy chủ có dung lượng cao hơn sẽ được gán nhiều node ảo hơn.
Sao chép dữ liệu (Data replication)
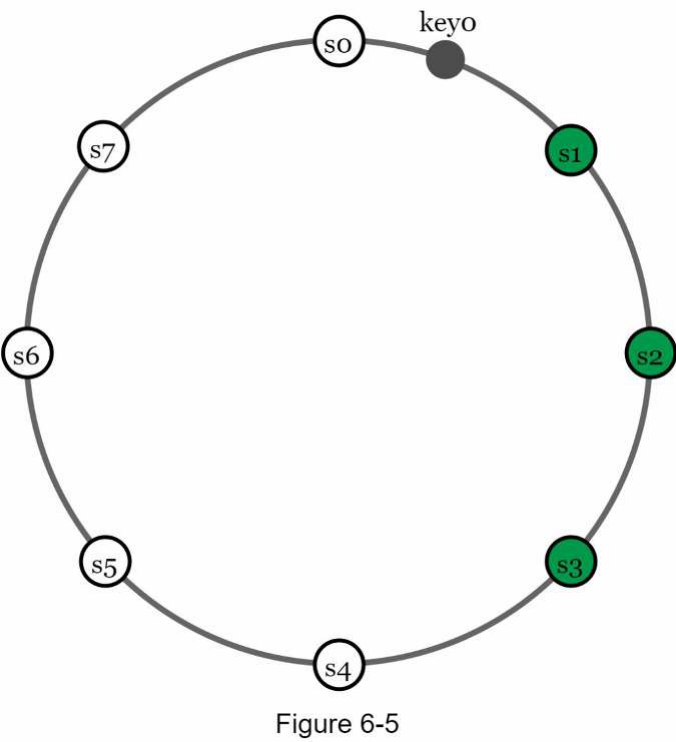
Để đạt được tính sẵn sàng cao (high availability) và độ tin cậy (reliability), dữ liệu phải được sao chép (replicated) bất đồng bộ trên N máy chủ, trong đó N là một tham số có thể cấu hình. Các máy chủ N này được chọn theo logic sau: sau khi một khóa (key) được ánh xạ tới một vị trí trên vòng băm (hash ring), chúng ta di chuyển theo chiều kim đồng hồ từ vị trí đó và chọn N máy chủ đầu tiên trên vòng để lưu trữ các bản sao dữ liệu. Trong Hình 6-5 ( N = 3 ), key0 được sao chép tại s1, s2 và s3.
Với các node ảo (virtual nodes), N node đầu tiên trên vòng có thể thuộc sở hữu của ít hơn N máy chủ vật lý. Để tránh vấn đề này, chúng ta chỉ chọn các máy chủ duy nhất (unique servers) khi thực hiện logic di chuyển theo chiều kim đồng hồ.
Các node trong cùng một trung tâm d�ữ liệu (data center) thường gặp sự cố cùng lúc do mất điện, sự cố mạng, thiên tai, v.v. Để có độ tin cậy tốt hơn, các bản sao được đặt ở các trung tâm dữ liệu khác nhau và các trung tâm dữ liệu được kết nối thông qua mạng tốc độ cao.
Tính nhất quán (Consistency)
Vì dữ liệu được sao chép tại nhiều node, nó phải được đồng bộ hóa (synchronized) giữa các bản sao. Cơ chế đồng thuận Quorum (Quorum consensus) có thể đảm bảo tính nhất quán cho cả hoạt động đọc và ghi. Trước tiên, chúng ta hãy thiết lập một vài định nghĩa.
N = Số lượng bản sao.
W = Một quorum ghi (write quorum) có kích thước W. Để một thao tác ghi được coi là thành công, thao tác ghi phải nhận được xác nhận (acknowledged) từ W bản sao.
R = Một quorum đọc (read quorum) có kích thước R. Để một thao tác đọc được coi là thành công, thao tác đọc phải chờ phản hồi từ ít nhất R bản sao.
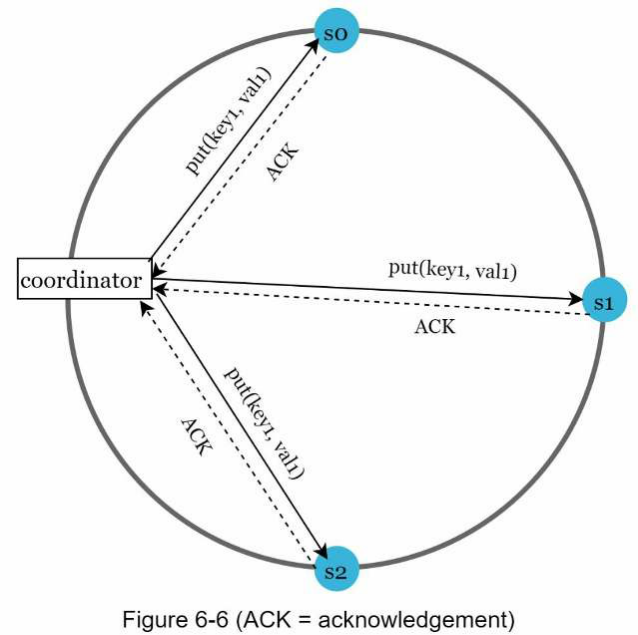
Hãy xem xét ví dụ sau được minh họa trong Hình 6-6 với N = 3.
W = 1 không có nghĩa là dữ liệu được ghi trên một máy chủ. Ví dụ, với cấu hình trong Hình 6-6, dữ liệu được sao chép tại s0, s1 và s2. W = 1 có nghĩa là điều phối viên (coordinator) phải nhận được ít nhất một xác nhận trước khi thao tác ghi được coi là thành công. Ví dụ, nếu chúng ta nhận được xác nhận từ s1, chúng ta không cần phải chờ xác nhận từ s0 và s2 nữa. Một điều phối viên hoạt động như một proxy giữa máy khách (client) và các node.
Cấu hình của W, R và N là một sự đánh đổi điển hình giữa độ trễ (latency) và tính nhất quán. Nếu W = 1 hoặc R = 1, một thao tác sẽ được trả về nhanh chóng vì điều phối viên chỉ cần chờ phản hồi từ bất kỳ bản sao nào. Nếu W hoặc R > 1, hệ thống sẽ cung cấp tính nhất quán tốt hơn; tuy nhiên, truy vấn sẽ chậm hơn vì điều phối viên phải chờ phản hồi từ bản sao chậm nhất.
Nếu W + R > N, tính nhất quán mạnh (strong consistency) được đảm bảo vì phải có ít nhất một
 node trùng lặp (overlapping node) chứa dữ liệu mới nhất để đảm bảo tính nhất quán.
node trùng lặp (overlapping node) chứa dữ liệu mới nhất để đảm bảo tính nhất quán.
Làm thế nào để cấu hình N, W và R cho phù hợp với các trường hợp sử dụng của chúng ta? Dưới đây là một số thiết lập khả thi:
- Nếu R = 1 và W = N, hệ thống được tối ưu hóa cho việc đọc nhanh.
- Nếu W = 1 và R = N, hệ thống được tối ưu hóa cho việc ghi nhanh.
- Nếu W + R > N, tính nhất quán mạnh được đảm bảo (Thông thường N = 3, W = R = 2 ).
- Nếu W + R <= N, tính nhất quán mạnh không được đảm bảo.
Tùy thuộc vào yêu cầu, chúng ta có thể điều chỉnh các giá trị của W, R, N để đạt được mức độ nhất quán mong muốn.
Các mô hình nhất quán (Consistency models) Mô hình nhất quán là một yếu tố quan trọng khác cần xem xét khi thiết kế một kho lưu trữ khóa-giá trị (key-value store). Một mô hình nhất quán định nghĩa mức độ nhất quán của dữ liệu, và có một phổ rộng các mô hình nhất quán khả thi:
-
Nhất quán mạnh: bất kỳ thao tác đọc nào cũng trả về một giá trị tương ứng với kết quả của mục dữ liệu ghi được cập nhật mới nhất. Máy khách không bao giờ thấy dữ liệu lỗi thời.
-
Nhất quán yếu: các thao tác đọc tiếp theo có thể không thấy giá trị được cập nhật mới nhất.
-
Nhất quán cuối cùng: đây là một dạng cụ thể của nhất quán yếu. Với đủ thời gian, tất cả các bản cập nhật sẽ được truyền đi và tất cả các bản sao sẽ nhất quán.
Nhất quán mạnh thường đạt được bằng cách buộc một bản sao không chấp nhận các thao tác đọc/ghi mới cho đến khi mọi bản sao đã đồng ý về bản ghi hiện tại. Cách tiếp cận này không lý tưởng cho các hệ thống có tính sẵn sàng cao vì nó có thể chặn các thao tác mới. Dynamo và Cassandra áp dụng nhất quán cuối cùng, đây là mô hình nhất quán được chúng ta khuyến nghị cho kho lưu trữ khóa-giá trị của chúng ta. Từ các thao tác ghi đồng thời (concurrent writes), nhất quán cuối cùng cho phép các giá trị không nhất quán đi vào hệ thống và buộc máy khách phải đọc các giá trị để đối chiếu (reconcile). Phần tiếp theo sẽ giải thích cách đối chiếu hoạt động với việc lập phiên bản (versioning).
Giải quyết xung đột dữ liệu: phiên bản hóa
Nhân bản (replication) mang lại tính sẵn sàng cao nhưng lại gây ra sự không nhất quán giữa các bản sao. Phiên bản hóa (versioning) và vector clock được sử dụng để giải quyết các vấn đề không nhất quán. Phiên bản hóa có nghĩa là coi mỗi lần sửa đổi dữ liệu là một phiên bản dữ liệu bất biến mới. Trước khi đi sâu vào phiên bản hóa, chúng ta hãy dùng một ví dụ để giải thích cách sự không nhất quán xảy ra:
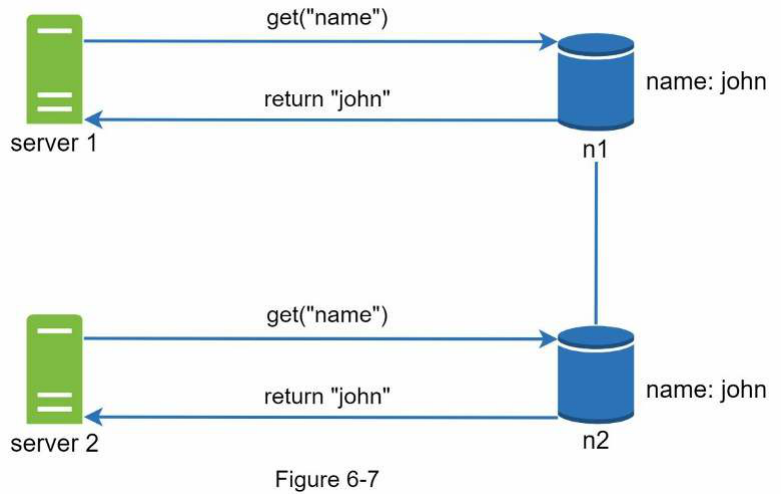
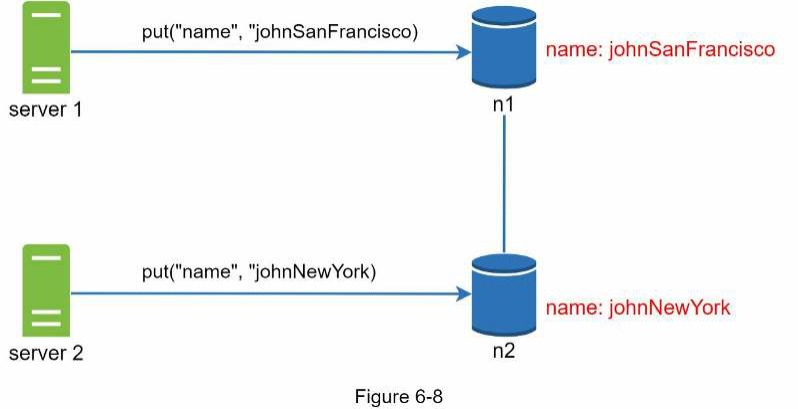
Như thể hiện trong Hình 6-7, cả hai node bản sao n1 và n2 đều có cùng một giá trị. Chúng ta hãy gọi giá trị này là giá trị gốc. Server 1 và server 2 nhận được cùng một giá trị cho thao tác get(“name”).
Tiếp theo, server 1 thay đổi tên thành “johnSanFrancisco”, và server 2 thay đổi tên thành “johnNewYork” như thể hiện trong Hình 6-8. Hai thay đổi này được thực hiện đồng thời. Bây giờ, chúng ta có các giá trị xung đột, được gọi là các phiên bản v1 và v2.
Trong ví dụ này, giá trị gốc có thể bị bỏ qua vì các sửa đổi đều dựa trên nó. Tuy nhiên, không có cách rõ ràng nào để giải quyết xung đột của hai phiên bản cuối cùng. Để giải quyết vấn đề này, chúng ta cần một hệ thống phiên bản hóa có thể phát hiện và hòa giải các xung đột. Một vector clock là một kỹ thuật phổ biến để giải quyết vấn đề này. Chúng ta hãy cùng tìm hiểu cách vector clock hoạt động.
 Một vector clock là một cặp [server, version] được liên kết với một mục dữ liệu. Nó có thể được sử dụng để kiểm tra xem một phiên bản có đi trước, đi sau, hay xung đột với các phiên bản khác hay không.
Một vector clock là một cặp [server, version] được liên kết với một mục dữ liệu. Nó có thể được sử dụng để kiểm tra xem một phiên bản có đi trước, đi sau, hay xung đột với các phiên bản khác hay không.
Giả sử một vector clock được biểu diễn bởi D([S1, v1], [S2, v2], …, [Sn, vn]), trong đó D là một mục dữ liệu, v1 là bộ đếm phiên bản, và s1 là số server, v.v. Nếu mục dữ liệu D được ghi vào server Si, hệ thống phải thực hiện một trong các tác vụ sau.
-
Tăng vi nếu [Si, vi] tồn tại.
-
Ngược lại, tạo một mục mới [Si, 1].
Logic trừu tượng trên được giải thích bằng một ví dụ cụ thể như thể hiện trong Hình 6-9.
- Một client ghi mục dữ liệu D1 vào hệ thống, và thao tác ghi này được xử lý bởi server Sx, hiện có vector clock D1[(Sx, 1)].
- Một client khác đọc D1 mới nhất, cập nhật nó thành D2, và ghi lại. D2 là hậu duệ của D1 nên nó ghi đè lên D1. Giả sử thao tác ghi được xử lý bởi cùng server Sx, hiện có vector clock D2([Sx, 2]).
- Một client khác đọc D2 mới nhất, cập nhật nó thành D3, và ghi lại. Giả sử thao tác ghi được xử lý bởi server Sy, hiện có vector clock D3([Sx, 2], [Sy, 1])).
- Một client khác đọc D2 mới nhất, cập nhật nó thành D4, và ghi lại. Giả sử thao tác ghi
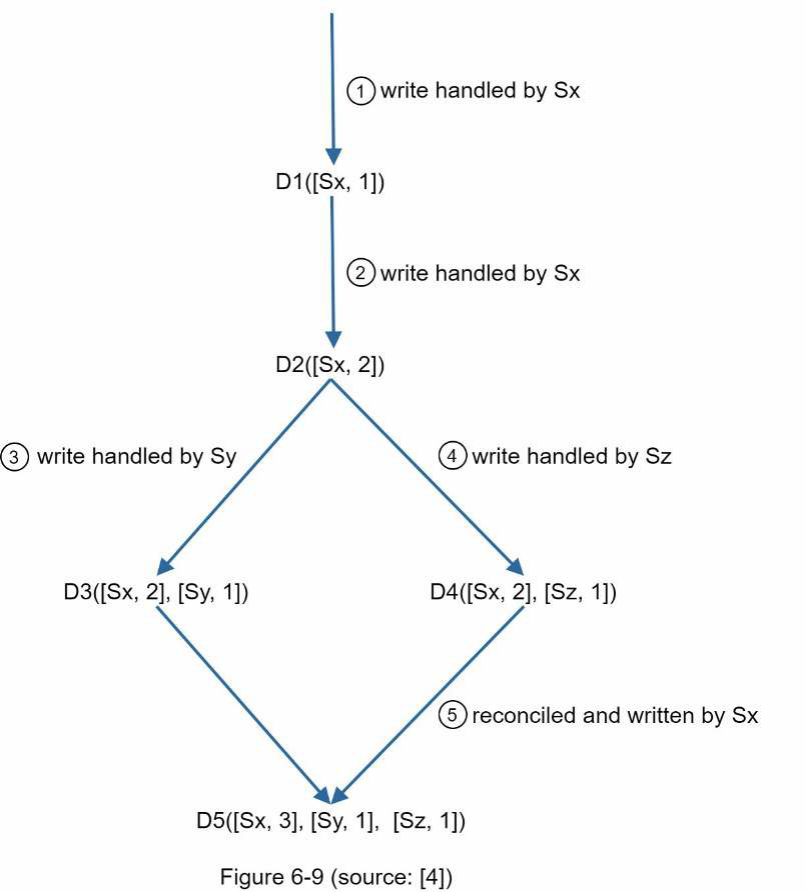 được xử lý bởi server Sz, hiện có D4([Sx, 2], [Sz, 1])).
5. Khi một client khác đọc D3 và D4, nó phát hiện một xung đột, nguyên nhân là do mục dữ liệu D2 đã bị sửa đổi bởi cả Sy và Sz. Xung đột được client giải quyết và dữ liệu đã cập nhật được gửi đến server. Giả sử thao tác ghi được xử lý bởi Sx, hiện có D5([Sx, 3], [Sy, 1], [Sz, 1]). Chúng ta sẽ giải thích cách phát hiện xung đột trong thời gian ngắn.
được xử lý bởi server Sz, hiện có D4([Sx, 2], [Sz, 1])).
5. Khi một client khác đọc D3 và D4, nó phát hiện một xung đột, nguyên nhân là do mục dữ liệu D2 đã bị sửa đổi bởi cả Sy và Sz. Xung đột được client giải quyết và dữ liệu đã cập nhật được gửi đến server. Giả sử thao tác ghi được xử lý bởi Sx, hiện có D5([Sx, 3], [Sy, 1], [Sz, 1]). Chúng ta sẽ giải thích cách phát hiện xung đột trong thời gian ngắn.
Sử dụng vector clock, chúng ta dễ dàng nhận biết rằng phiên bản X là tổ tiên (tức là không có xung đột) của phiên bản Y nếu các bộ đếm phiên bản cho mỗi thành phần trong vector clock của Y lớn hơn hoặc bằng các bộ đếm tương ứng trong phiên bản X. Ví dụ, vector clock D([s0, 1], [s1, 1]) là tổ tiên của D([s0, 1], [s1, 2]). Do đó, không có xung đột nào được ghi nhận.
Tương tự, chúng ta có thể nhận biết rằng phiên bản X là phiên bản ngang hàng (tức là tồn tại xung đột) của Y nếu có bất kỳ thành phần nào trong vector clock của Y có bộ đếm nhỏ hơn bộ đếm tương ứng của nó trong X. Ví dụ, hai vector clock sau đây cho thấy có xung đột: D([s0, 1], [s1, 2]) và D([s0, 2], [s1, 1]).
Mặc dù vector clock có thể giải quyết xung đột, nhưng có hai nhược điểm đáng chú ý. Đầu tiên, vector clock làm tăng độ phức tạp cho client vì client cần phải triển khai logic giải quyết xung đột.
Thứ hai, các cặp [server: version] trong vector clock có thể phát triển nhanh chóng. Để khắc phục vấn đề này, chúng ta đặt một ngưỡng cho độ dài, và nếu nó vượt quá giới hạn, các cặp cũ nhất sẽ bị xóa. Điều này có thể dẫn đến sự kém hiệu quả trong việc hòa giải vì mối quan hệ hậu duệ không thể được xác định chính xác. Tuy nhiên, dựa trên tài liệu Dynamo [4], Amazon vẫn chưa gặp phải vấn đề này trong môi trường sản xuất; do đó, đây có lẽ là một giải pháp chấp nhận được đối với hầu hết các công ty.
Xử lý lỗi
Giống như bất kỳ hệ thống lớn nào ở quy mô lớn, lỗi không chỉ là điều không thể tránh khỏi mà còn rất phổ biến. Xử lý các kịch bản lỗi là vô cùng quan trọng. Trong phần này, trước tiên chúng ta sẽ giới thiệu các kỹ thuật để phát hiện lỗi. Sau đó, chúng ta sẽ xem xét các chiến lược giải quyết lỗi phổ biến.
Phát hiện lỗi Trong một hệ thống phân tán, việc tin rằng một máy chủ bị lỗi chỉ vì một máy chủ khác nói vậy là không đủ. Thông thường, cần ít nhất hai nguồn thông tin độc lập để đánh dấu một máy chủ là bị lỗi.
Như minh họa trong Hình 6-10, đa hướng (multicasting) tất cả-đến-tất cả là một giải pháp đơn giản. Tuy nhiên, điều này không hiệu quả khi có nhiều máy chủ trong hệ thống.
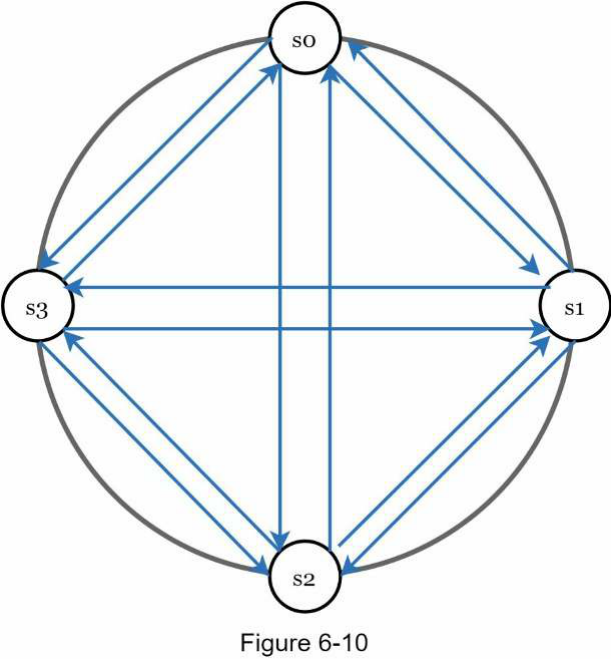
Một giải pháp tốt hơn là sử dụng các phương pháp phát hiện lỗi phi tập trung như gossip protocol (tiếng Anh: gossip protocol). Gossip protocol hoạt động như sau:
-
Mỗi node (nút) duy trì một danh sách thành viên node, chứa ID thành viên và bộ đếm heartbeat (nhịp tim).
-
Mỗi node định kỳ tăng bộ đếm heartbeat của nó.
-
Mỗi node định kỳ gửi heartbeats đến một tập hợp các node ngẫu nhiên, các node này sau đó sẽ lan truyền đến một tập hợp các node khác.
-
Khi các node nhận được heartbeats, danh sách thành viên sẽ được cập nhật với thông tin mới nhất.
-
Nếu heartbeat không tăng trong hơn các khoảng thời gian được định nghĩa trước, thành viên đó được coi là ngoại tuyến.
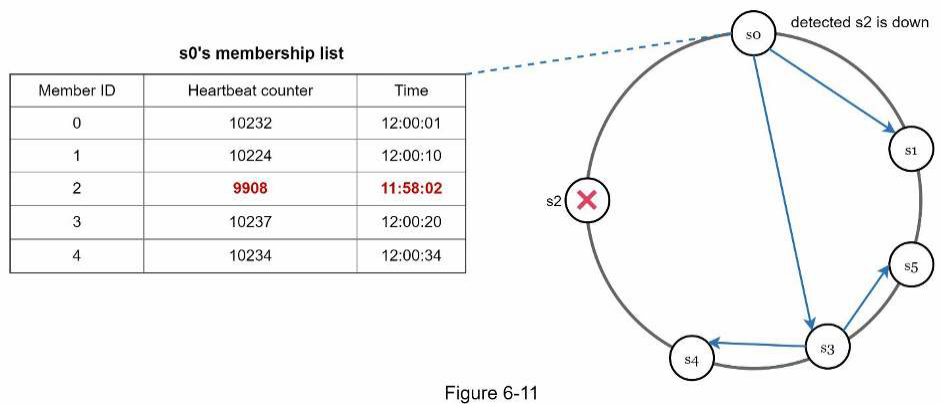
Như minh họa trong Hình 6-11:
-
Node s0 duy trì một danh sách thành viên node được hiển thị ở phía bên trái.
-
Node s0 nhận thấy rằng bộ đếm heartbeat của node s2 (ID thành viên = 2) đã không tăng trong một thời gian dài.
-
Node s0 gửi các heartbeat bao gồm thông tin của s2 đến một tập hợp các node ngẫu nhiên. Khi các node khác xác nhận rằng bộ đếm heartbeat của s2 đã không được cập nhật trong một thời gian dài, node s2 sẽ được đánh dấu là bị lỗi, và thông tin này được lan truyền đến các node khác.
Xử lý các lỗi tạm thời Sau khi các lỗi đã được phát hiện thông qua gossip protocol, hệ thống cần triển khai các cơ chế nhất định để đảm bảo tính khả dụng. Trong cách tiếp cận quorum (tiếng Anh: quorum) nghiêm ngặt, các hoạt động đọc và ghi có thể bị chặn như đã minh họa trong phần đồng thuận quorum.
Một kỹ thuật gọi là “sloppy quorum” (tiếng Anh: sloppy quorum) [4] được sử dụng để cải thiện tính khả dụng. Thay vì thực thi yêu cầu quorum, hệ thống chọn W máy chủ khỏe mạnh đầu tiên cho các thao tác ghi và R máy chủ khỏe mạnh đầu tiên cho các thao tác đọc trên vòng băm (hash ring). Các máy ch��ủ ngoại tuyến sẽ bị bỏ qua.
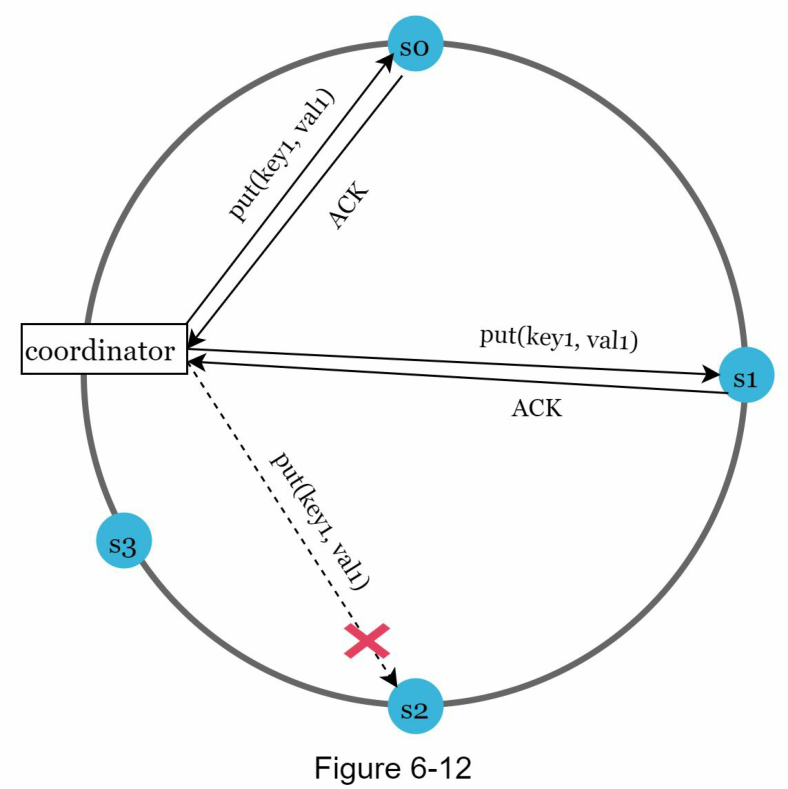
Nếu một máy chủ không khả dụng do lỗi mạng hoặc máy chủ, một máy chủ khác sẽ xử lý các yêu cầu tạm thời. Khi máy chủ bị lỗi hoạt động trở lại, các thay đổi sẽ được đẩy ngược lại để đạt được tính nhất quán của dữ liệu. Quá trình này được gọi là hinted handoff (tiếng Anh: hinted handoff). Vì s2 không khả dụng trong Hình 6-12, các thao tác đọc và ghi sẽ được s3 xử lý tạm thời. Khi s2 hoạt động trở lại, s3 sẽ chuyển dữ liệu lại cho s2.
Xử lý các lỗi vĩnh viễn
 Hinted handoff được sử dụng để xử lý các lỗi tạm thời. Điều gì sẽ xảy ra nếu một bản sao (replica) không khả dụng vĩnh viễn? Để xử lý tình huống như vậy, chúng ta triển khai một anti-entropy protocol (tiếng Anh: anti-entropy protocol) để giữ cho các bản sao đồng bộ. Anti-entropy bao gồm việc so sánh từng phần dữ liệu trên các bản sao và cập nhật mỗi bản sao lên phiên bản mới nhất. Một Merkle tree (tiếng Anh: Merkle tree) được sử dụng để phát hiện sự không nhất quán và giảm thiểu lượng dữ liệu được truyền tải.
Hinted handoff được sử dụng để xử lý các lỗi tạm thời. Điều gì sẽ xảy ra nếu một bản sao (replica) không khả dụng vĩnh viễn? Để xử lý tình huống như vậy, chúng ta triển khai một anti-entropy protocol (tiếng Anh: anti-entropy protocol) để giữ cho các bản sao đồng bộ. Anti-entropy bao gồm việc so sánh từng phần dữ liệu trên các bản sao và cập nhật mỗi bản sao lên phiên bản mới nhất. Một Merkle tree (tiếng Anh: Merkle tree) được sử dụng để phát hiện sự không nhất quán và giảm thiểu lượng dữ liệu được truyền tải.
Trích dẫn từ Wikipedia [7]: “Cây băm (hash tree) hay Merkle tree là một cây mà mỗi node không phải lá được gán nhãn bằng giá trị băm của các nhãn hoặc giá trị (trong trường hợp là lá) của các node con của nó. Cây băm cho phép xác minh hiệu quả và an toàn nội dung của các cấu trúc dữ liệu lớn”.
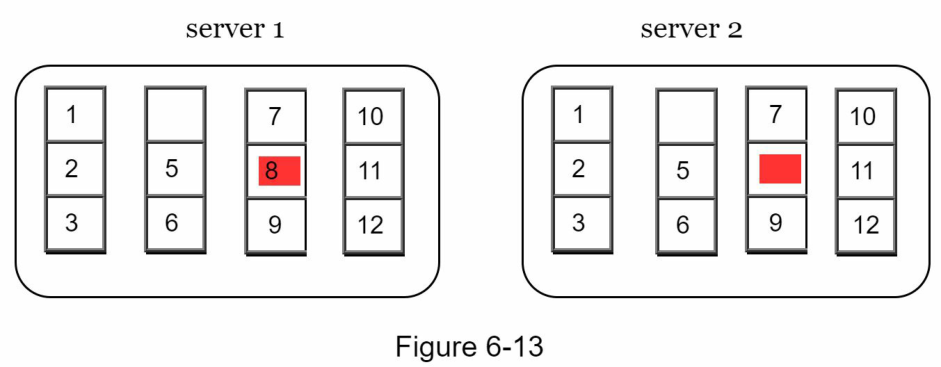
Giả sử không gian khóa (key space) từ 1 đến 12, các bước sau đây cho thấy cách xây dựng một Merkle tree. Các ô được tô sáng chỉ ra sự không nhất quán.
Bước 1: Chia không gian khóa thành các bucket (4 trong ví dụ của chúng ta) như minh họa trong Hình 6-13. Một bucket được sử dụng làm node cấp gốc để duy trì độ sâu giới hạn của cây.
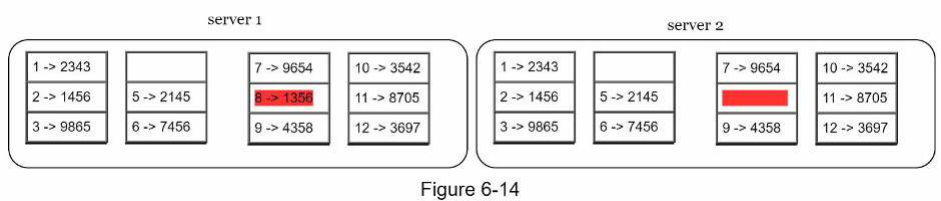
Bước 2: Sau khi các bucket được tạo, băm mỗi khóa trong một bucket bằng cách sử dụng phương pháp băm đồng nhất (uniform hashing method) (Hình 6-14).
Bước 3: Tạo một node băm duy nhất cho mỗi bucket (Hình 6-15).
Bước 4: Xây dựng cây từ dưới lên đến gốc bằng cách tính toán giá trị băm của các node con (Hình 6-16).
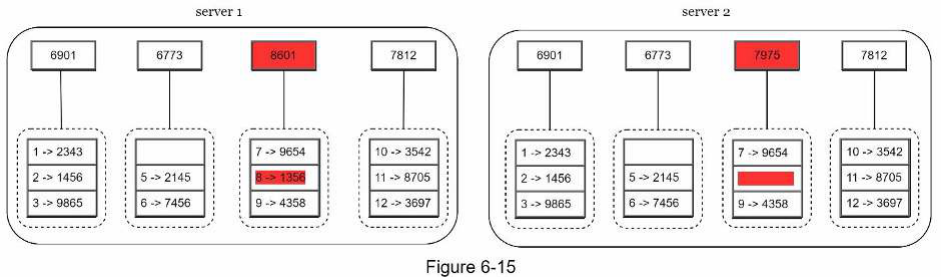
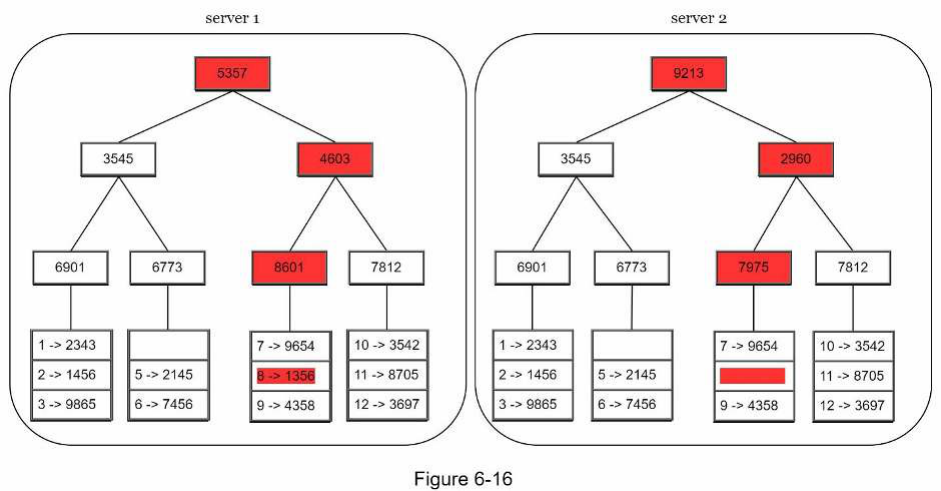
Để so sánh hai Merkle tree, hãy bắt đầu bằng cách so sánh các giá trị băm gốc (root hashes). Nếu các giá trị băm gốc khớp nhau, cả hai máy chủ đều có cùng dữ liệu. Nếu các giá trị băm gốc không khớp, thì các giá trị băm của node con bên trái được so sánh, sau đó là các giá trị băm của node con bên phải. Chúng ta có thể duyệt cây để tìm ra những bucket nào không được đồng bộ hóa và chỉ đồng bộ hóa những bucket đó.
Sử dụng Merkle tree, lượng dữ liệu cần được đồng bộ hóa tỷ lệ thuận với sự khác biệt giữa hai bản sao, chứ không phải tổng lượng dữ liệu mà chúng chứa. Trong các hệ thống thực tế, kích thước bucket khá lớn. Ví dụ, một cấu hình khả thi là một triệu bucket cho mỗi một tỷ khóa, vì vậy mỗi bucket chỉ chứa 1000 khóa.
Xử lý sự cố trung tâm dữ liệu Sự cố trung tâm dữ liệu (data center outage) có thể xảy ra do mất điện, mất mạng, thiên tai, v.v. Để xây dựng một hệ thống có khả năng xử lý sự cố trung tâm dữ liệu, điều quan trọng là phải sao chép dữ liệu trên nhiều trung tâm dữ liệu. Ngay cả khi một trung tâm dữ liệu hoàn toàn ngoại tuyến, người dùng vẫn có thể truy cập dữ liệu thông qua các trung tâm dữ liệu khác.
Sơ đồ kiến trúc hệ thống
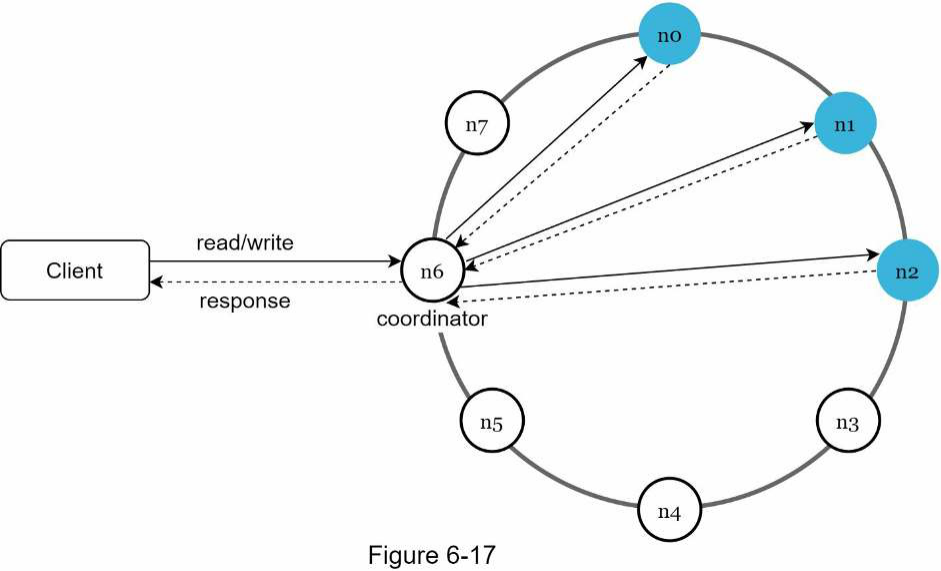
Giờ đây, khi chúng ta đã thảo luận về các cân nhắc kỹ thuật khác nhau trong việc thiết kế một kho lưu trữ key-value, chúng ta có thể chuyển trọng tâm sang sơ đồ kiến trúc, được hiển thị trong Hình 6-17.
Các tính năng chính của kiến trúc được liệt kê như sau:
-
Client (ứng dụng khách) giao tiếp với kho lưu trữ key-value thông qua các API đơn giản: get(key) và put(key, value).
-
Một coordinator (điều phối viên) là một node đóng vai trò proxy giữa client và kho lưu trữ key-value.
-
Các node được phân tán trên một vòng bằng cách sử dụng consistent hashing (tiếng Anh: consistent hashing).
-
Hệ thống hoàn toàn phi tập trung nên việc thêm và di chuyển các node có thể tự động.
-
Dữ liệu được sao chép tại nhiều node.
-
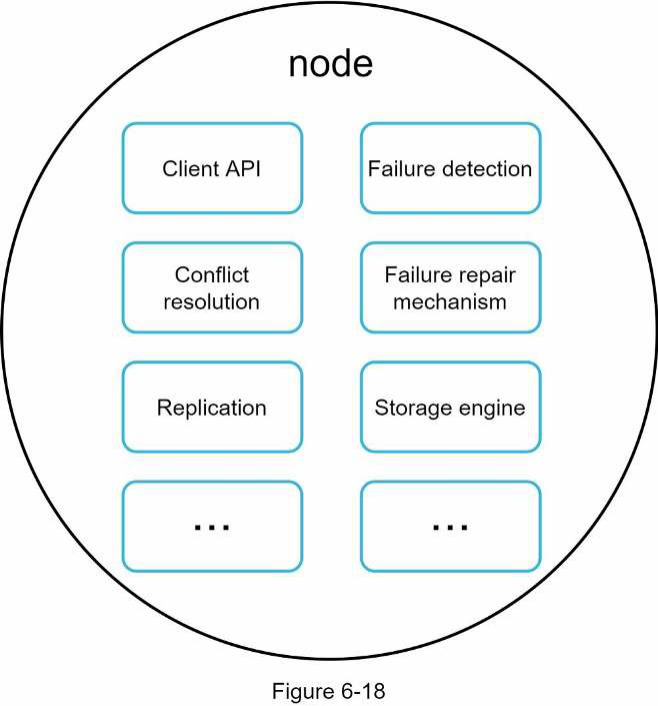
Không có điểm lỗi duy nhất (single point of failure) vì mỗi node đều có cùng một tập hợp trách nhiệm. Vì thiết kế là phi tập trung, mỗi node thực hiện nhiều tác vụ như được trình bày trong Hình 6-18.
Luồng ghi (Write path)
Hình 6-19 giải thích những gì xảy ra sau khi một yêu cầu ghi được chuyển đến một node cụ thể. Xin lưu ý rằng các thiết kế được đề xuất cho luồng ghi/đọc chủ yếu dựa trên kiến trúc của Cassandra [8].
- Yêu cầu ghi được lưu trữ bền vững vào một tệp commit log (tiếng Anh: commit log).
- Dữ liệu được lưu vào bộ nhớ cache.
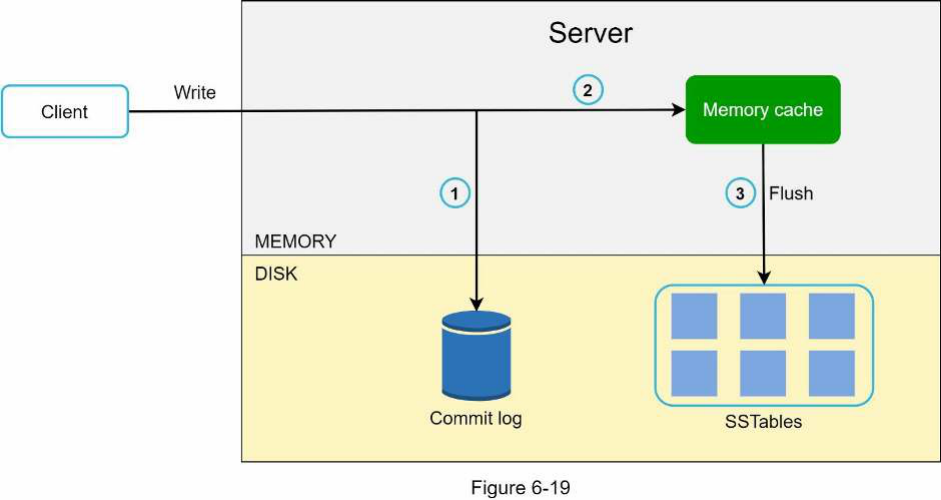 3. Khi bộ nhớ cache đầy hoặc đạt đến ngưỡng được định nghĩa trước, dữ liệu sẽ được đẩy (flush) vào SSTable (tiếng Anh: SSTable) [9] trên đĩa. Lưu ý: Một sorted-string table (SSTable) là một danh sách được sắp xếp các cặp
3. Khi bộ nhớ cache đầy hoặc đạt đến ngưỡng được định nghĩa trước, dữ liệu sẽ được đẩy (flush) vào SSTable (tiếng Anh: SSTable) [9] trên đĩa. Lưu ý: Một sorted-string table (SSTable) là một danh sách được sắp xếp các cặp <key, value>. Đối với những độc giả quan tâm đến việc tìm hiểu thêm về SSTable, hãy tham khảo tài liệu tham khảo [9].
Luồng đọc (Read path)
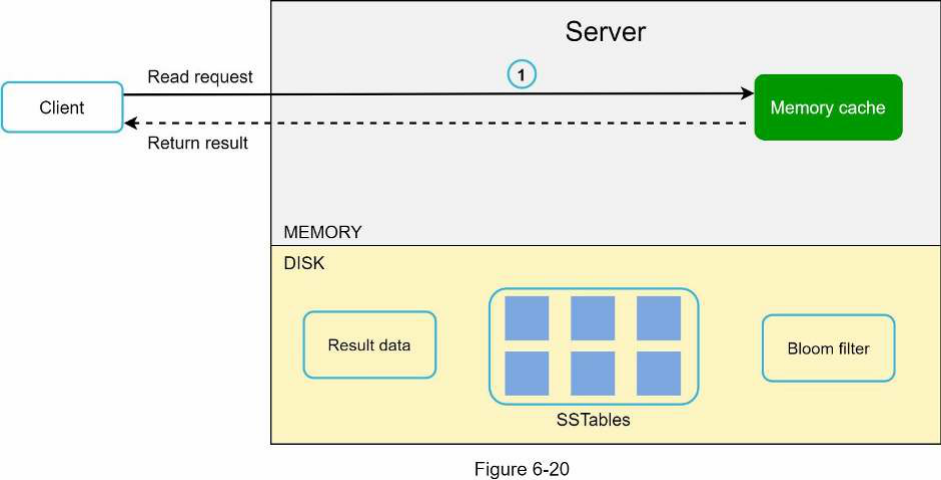
Sau khi một yêu cầu đọc được chuyển đến một node cụ thể, nó trước tiên kiểm tra xem dữ liệu có trong bộ nhớ cache hay không. Nếu có, dữ liệu sẽ được trả về client như minh họa trong Hình 6-20.
Nếu dữ liệu không có trong bộ nhớ, nó sẽ được truy xuất từ đĩa thay thế. Chúng ta cần một cách hiệu quả để tìm ra SSTable nào chứa khóa. Bloom filter (tiếng Anh: Bloom filter) [10] thường được sử dụng để giải quyết vấn đề này.
Luồng đọc được hiển thị trong Hình 6-21 khi dữ liệu không có trong bộ nhớ.
- Hệ thống trước tiên kiểm tra xem dữ liệu có trong bộ nhớ hay không. Nếu không, chuyển sang bước 2.
- Nếu dữ liệu không có trong bộ nhớ, hệ thống kiểm tra bloom filter.
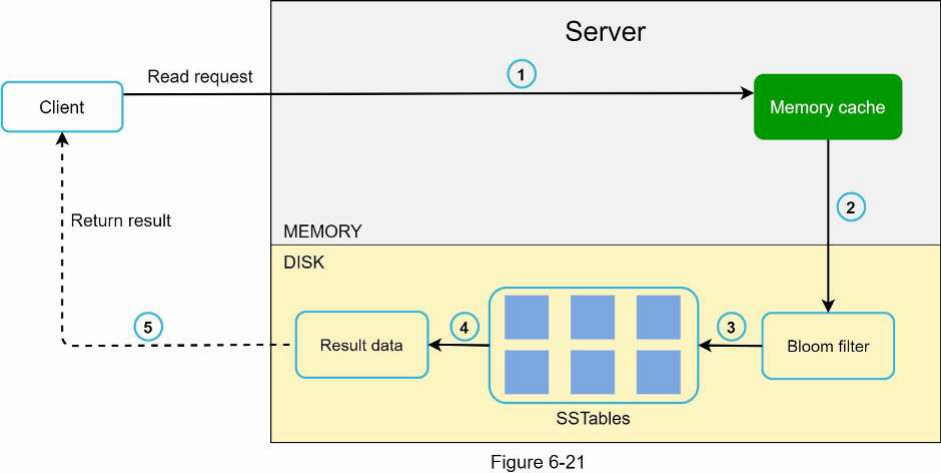 3. Bloom filter được sử dụng để tìm ra những SSTable nào có thể chứa khóa.
4. Các SSTable trả về kết quả của tập dữ liệu.
5. Kết quả của tập dữ liệu được trả về client.
3. Bloom filter được sử dụng để tìm ra những SSTable nào có thể chứa khóa.
4. Các SSTable trả về kết quả của tập dữ liệu.
5. Kết quả của tập dữ liệu được trả về client.
3. Bloom filter được dùng để xác định SSTable nào có thể chứa khóa.
4. Các SSTable trả về kết quả của tập dữ liệu.
5. Kết quả của tập dữ liệu được trả về cho client.
Tóm tắt
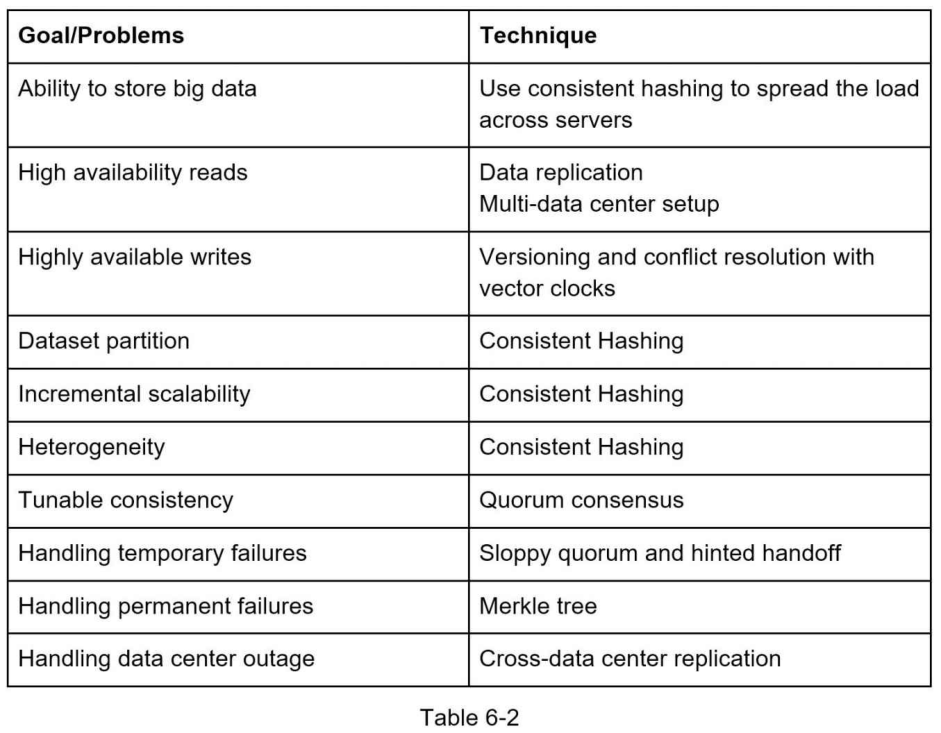
Chương này đã đề cập đến nhiều khái niệm và kỹ thuật. Để giúp chúng ta ôn lại, bảng sau tóm tắt các tính năng và kỹ thuật tương ứng được sử dụng cho một hệ thống lưu trữ khóa-giá trị phân tán (tiếng Anh: distributed key-value store).
Tài liệu tham khảo
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
[2] memcached: https://memcached.org/
[3] Redis: https://redis.io/
[4] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[5] Cassandra: https://cassandra.apache.org/
[6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtableosdi06.pdf
[7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
[8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
[9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
[10] Bloom filter https://en.wikipedia.org/wiki/Bloom_filter
Made by Anh Tu - Share to be share