[System design interview] CHƯƠNG 1: MỞ RỘNG TỪ CON SỐ 0 ĐẾN HÀNG TRIỆU NGƯỜI DÙNG

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
CHƯƠNG 1: MỞ RỘNG TỪ CON SỐ 0 ĐẾN HÀNG TRIỆU NGƯỜI DÙNG
Thiết kế một hệ thống hỗ trợ hàng triệu người dùng là một thách thức, và đó là một hành trình đòi hỏi sự tinh chỉnh liên tục và cải tiến không ngừng. Trong chương này, chúng ta sẽ xây dựng một hệ thống hỗ trợ một người dùng duy nhất và dần dần mở rộng nó để phục vụ hàng triệu người dùng. Sau khi đọc chương này, bạn sẽ nắm vững một số kỹ thuật giúp bạn vượt qua các câu hỏi phỏng vấn về thiết kế hệ thống.
Thiết lập máy chủ đơn lẻ
Hành trình vạn dặm bắt đầu từ một bước chân, và việc xây dựng một hệ thống phức tạp cũng không khác biệt. Để bắt đầu với một cái gì đó đơn giản, mọi thứ đều chạy trên một máy chủ duy nhất. Hình 1-1 minh họa thiết lập máy chủ đơn lẻ, nơi mọi thứ đều chạy trên một máy chủ: ứng dụng web, cơ sở dữ liệu, bộ nhớ đệm (tiếng Anh: cache), v.v.
Để hiểu thiết lập này, việc tìm hiểu luồng yêu cầu (tiếng Anh: request flow) và nguồn lưu lượng truy cập (tiếng Anh: traffic source) là rất hữu ích. Trước tiên, chúng ta hãy xem xét luồng yêu cầu (Hình 1-2).
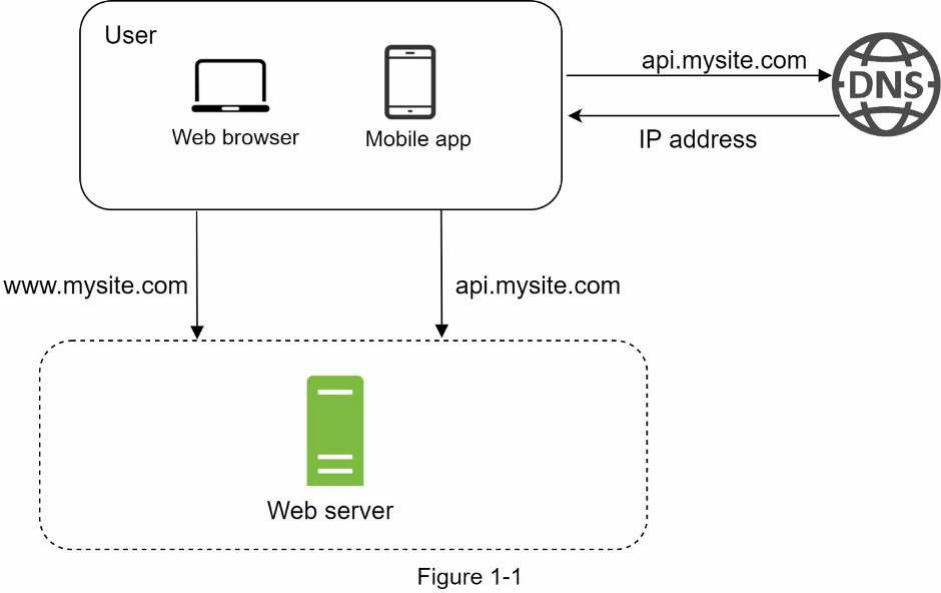
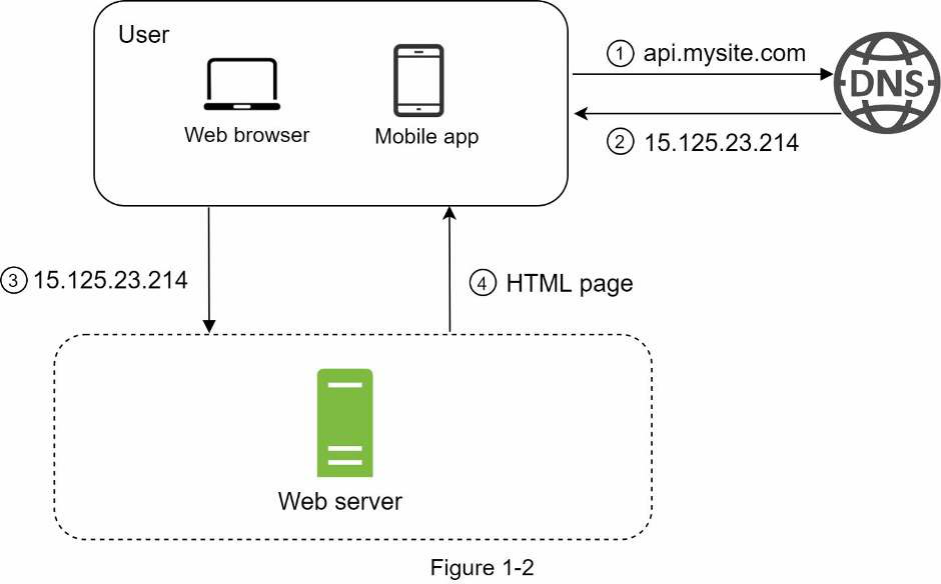
- Người dùng truy cập các trang web thông qua tên miền (domain name), chẳng hạn như api.mysite.com. Thông thường, Hệ thống Tên miền (Domain Name System - DNS) là một dịch vụ trả phí do bên thứ ba cung cấp và không được máy chủ của chúng ta lưu trữ.
- Địa chỉ Giao thức Internet (Internet Protocol - IP) được trả về trình duyệt hoặc ứng dụng di động. Trong ví dụ này, địa chỉ IP 15.125.23.214 được trả về.
- Sau khi có được địa chỉ IP, các yêu cầu HTTP [1] được gửi trực tiếp đến máy chủ web của bạn.
- Máy chủ web trả về các trang HTML hoặc phản hồi JSON để hiển thị.
Tiếp theo, chúng ta hãy xem xét nguồn lưu lượng truy cập. Lưu lượng truy cập đến máy chủ web của bạn đến từ hai nguồn: ứng dụng web và ứng dụng di động.
-
Ứng dụng web: nó sử dụng sự kết hợp của các ngôn ngữ phía máy chủ (tiếng Anh: server-side languages) (Java, Python, v.v.) để xử lý logic nghiệp vụ (tiếng Anh: business logic), lưu trữ, v.v., và các ngôn ngữ phía máy khách (tiếng Anh: client-side languages) (HTML và JavaScript) để trình bày.
-
Ứng dụng di động: giao thức HTTP là giao thức giao tiếp giữa ứng dụng di động và máy chủ web. JavaScript Object Notation (JSON) là định dạng phản hồi API (tiếng Anh: API response format) thường đư��ợc sử dụng để truyền dữ liệu nhờ sự đơn giản của nó. Một ví dụ về phản hồi API ở định dạng JSON được hiển thị bên dưới:
GET /users/12 – Truy xuất đối tượng người dùng có id = 12

Cơ sở dữ liệu
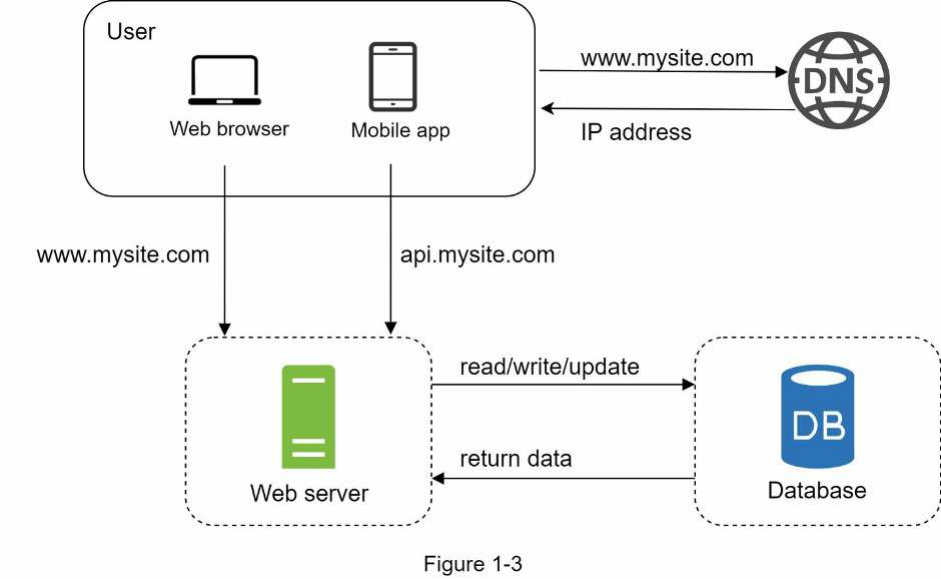
Với sự phát triển của lượng người dùng, một máy chủ là không đủ, và chúng ta cần nhiều máy chủ: một cho lưu lượng web/di động, và một cho cơ sở dữ liệu (Hình 1-3). Việc tách biệt lưu lượng web/di động (tầng web - tiếng Anh: web tier) và máy chủ cơ sở dữ liệu (tầng dữ liệu - tiếng Anh: data tier) cho phép chúng được mở rộng độc lập.
Nên sử dụng loại cơ sở dữ liệu nào?
Bạn có thể lựa chọn giữa cơ sở dữ liệu quan hệ (tiếng Anh: relational database) truyền thống và cơ sở dữ liệu phi quan hệ (tiếng Anh: non-relational database). Chúng ta hãy xem xét sự khác biệt của chúng.
Cơ sở dữ liệu quan hệ còn được gọi là hệ quản trị cơ sở dữ liệu quan hệ (relational database management system - RDBMS) hoặc cơ sở dữ liệu SQL. Các loại phổ biến nhất là MySQL, Oracle database, PostgreSQL, v.v. Cơ sở dữ liệu quan hệ biểu diễn và lưu trữ dữ liệu dưới dạng bảng và hàng. Bạn có thể thực hiện các thao tác join (kết nối) (tiếng Anh: join operations) bằng SQL trên các bảng cơ sở dữ liệu khác nhau.
Cơ sở dữ liệu phi quan hệ còn được gọi là cơ sở dữ liệu NoSQL. Các loại phổ biến là CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB, v.v. [2]. Các cơ sở dữ liệu này được nhóm thành bốn loại: kho khóa-giá trị (tiếng Anh: key-value stores), kho đồ thị (tiếng Anh: graph stores), kho cột (tiếng Anh: column stores), và kho tài liệu (tiếng Anh: document stores). Các thao tác join thường không được hỗ trợ trong cơ sở dữ liệu phi quan hệ.
Đối với hầu hết các nhà phát triển, cơ sở dữ liệu quan hệ là lựa chọn tốt nhất vì chúng đã tồn tại hơn 40 năm và trong lịch sử, chúng đã hoạt động hiệu quả. Tuy nhiên, nếu cơ sở dữ liệu quan hệ không phù hợp với các trường hợp sử dụng (tiếng Anh: use cases) cụ thể của bạn, việc tìm hiểu các loại cơ sở dữ liệu khác ngoài cơ sở dữ liệu quan hệ là rất quan trọng. Cơ sở dữ liệu phi quan hệ có thể là lựa chọn phù hợp nếu:
-
Ứng dụng của bạn yêu cầu độ trễ cực thấp (tiếng Anh: super-low latency).
-
Dữ liệu của bạn không có cấu trúc (tiếng Anh: unstructured) hoặc bạn không có bất kỳ dữ liệu quan hệ nào.
-
Bạn chỉ cần tuần tự hóa (tiếng Anh: serialize) và giải tuần tự hóa (tiếng Anh: deserialize) dữ liệu (JSON, XML, YAML, v.v.).
-
Bạn cần lưu trữ một lư�ợng lớn dữ liệu.
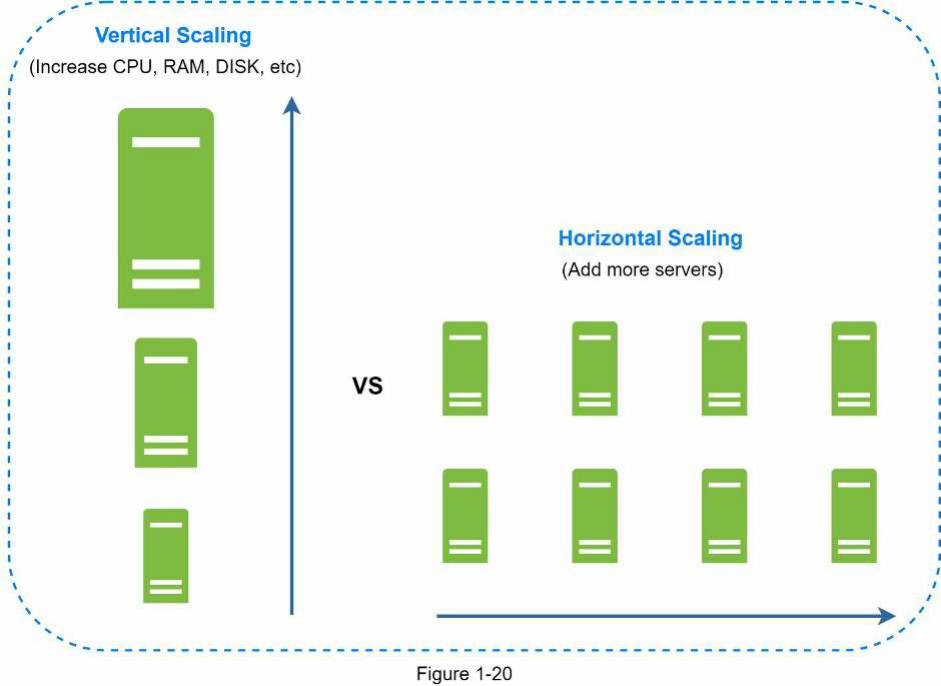
Mở rộng theo chiều dọc (Vertical scaling) so với mở rộng theo chiều ngang (Horizontal scaling)
Mở rộng theo chiều dọc (tiếng Anh: Vertical scaling), còn gọi là “scale up” (tiếng Anh: scale up), là quá trình tăng thêm sức mạnh (CPU, RAM, v.v.) cho máy chủ của bạn. Mở rộng theo chiều ngang (tiếng Anh: Horizontal scaling), còn gọi là “scale-out” (tiếng Anh: scale-out), cho phép bạn mở rộng bằng cách thêm nhiều máy chủ vào nhóm tài
Sao chép cơ sở dữ liệu
Trích từ Wikipedia: “Sao chép cơ sở dữ liệu (Database replication) có thể được sử dụng trong nhiều hệ thống quản lý cơ sở dữ liệu, thường với mối quan hệ master/slave giữa bản gốc (master) và các bản sao (slaves)” [3].
Một cơ sở dữ liệu master (chính) thường chỉ hỗ trợ các thao tác ghi. Một cơ sở dữ liệu slave (phụ) nhận các bản sao dữ liệu từ cơ sở dữ liệu master và chỉ hỗ trợ các thao tác đọc. Tất cả các lệnh sửa đổi dữ liệu như insert (thêm), delete (xóa) hoặc update (cập nhật) phải được gửi đến cơ sở dữ liệu master. Hầu hết các ứng dụng yêu cầu tỷ lệ đọc trên ghi cao hơn nhiều; do đó, số lượng cơ sở dữ liệu slave trong một hệ thống thường lớn hơn số lượng cơ sở dữ liệu master. Hình 1-5 minh họa một cơ sở dữ liệu master với nhiều cơ sở dữ liệu slave.
Ưu điểm của sao chép cơ sở dữ liệu:
-
Hiệu suất tốt hơn: Trong mô hình master-slave, tất cả các thao tác ghi và cập nhật diễn ra trên các node master; trong khi đó, các thao tác đọc được phân phối trên các node slave. Mô hình này cải thiện hiệu suất vì nó cho phép nhiều truy vấn được xử lý song song.
-
Độ tin cậy: Nếu một trong các máy chủ cơ sở dữ liệu của chúng ta bị phá hủy bởi một thảm họa thiên nhiên, chẳng hạn như bão hoặc động đất, dữ liệu vẫn được bảo toàn. Chúng ta không cần lo lắng về việc mất dữ liệu vì dữ liệu được sao chép trên nhiều vị trí.
-
Tính sẵn sàng cao (High availability): Bằng cách sao chép dữ liệu trên các vị trí khác nhau, trang web của chúng ta vẫn hoạt động
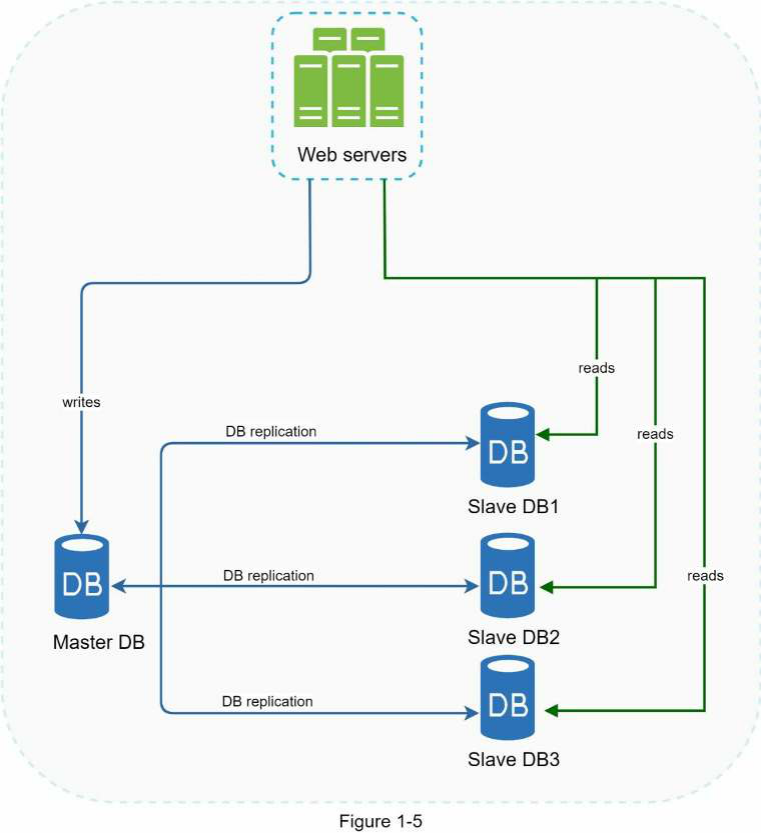 ngay cả khi một cơ sở dữ liệu ngoại tuyến vì chúng ta có thể truy cập dữ liệu được lưu trữ trên một máy chủ cơ sở dữ liệu khác.
ngay cả khi một cơ sở dữ liệu ngoại tuyến vì chúng ta có thể truy cập dữ liệu được lưu trữ trên một máy chủ cơ sở dữ liệu khác.
Trong phần trước, chúng ta đã thảo luận về cách một load balancer (bộ cân bằng tải) giúp cải thiện tính sẵn sàng của hệ thống. Chúng ta đặt câu hỏi tương tự ở đây: điều gì sẽ xảy ra nếu một trong các cơ sở dữ liệu ngoại tuyến? Thiết kế kiến trúc được thảo luận trong Hình 1-5 có thể xử lý trường hợp này:
-
Nếu chỉ có một cơ sở dữ liệu slave khả dụng và nó ngoại tuyến, các thao tác đọc sẽ tạm thời được chuyển hướng đến cơ sở dữ liệu master. Ngay sau khi vấn đề được phát hiện, một cơ sở dữ liệu slave mới sẽ thay thế cái cũ. Trong trường hợp có nhiều cơ sở dữ liệu slave khả dụng, các thao tác đọc sẽ được chuyển hướng đến các cơ sở dữ liệu slave khỏe mạnh khác. Một máy chủ cơ sở dữ liệu mới sẽ thay thế cái cũ.
-
Nếu cơ sở dữ liệu master ngoại tuyến, một cơ sở dữ liệu slave sẽ được thăng cấp thành master mới. Tất cả các thao tác cơ sở dữ liệu sẽ tạm thời được thực thi trên cơ sở dữ liệu master mới. Một cơ sở dữ liệu slave mới sẽ thay thế cái cũ để sao chép dữ liệu ngay lập tức. Trong các hệ thống sản xuất, việc thăng cấp một master mới phức tạp hơn vì dữ liệu trong cơ sở dữ liệu slave có thể không được cập nhật. Dữ liệu bị thiếu cần được cập nhật bằng cách chạy các script khôi phục dữ liệu. Mặc dù một số phương pháp sao chép khác như multi-masters (nhiều master) và circular replication (sao chép vòng tròn) có thể hữu ích, nhưng các thiết lập đó phức tạp hơn; và việc thảo luận về chúng nằm ngoài phạm vi của cuốn sách này. Độc giả quan tâm nên tham khảo các tài liệu được liệt kê [4] [5].
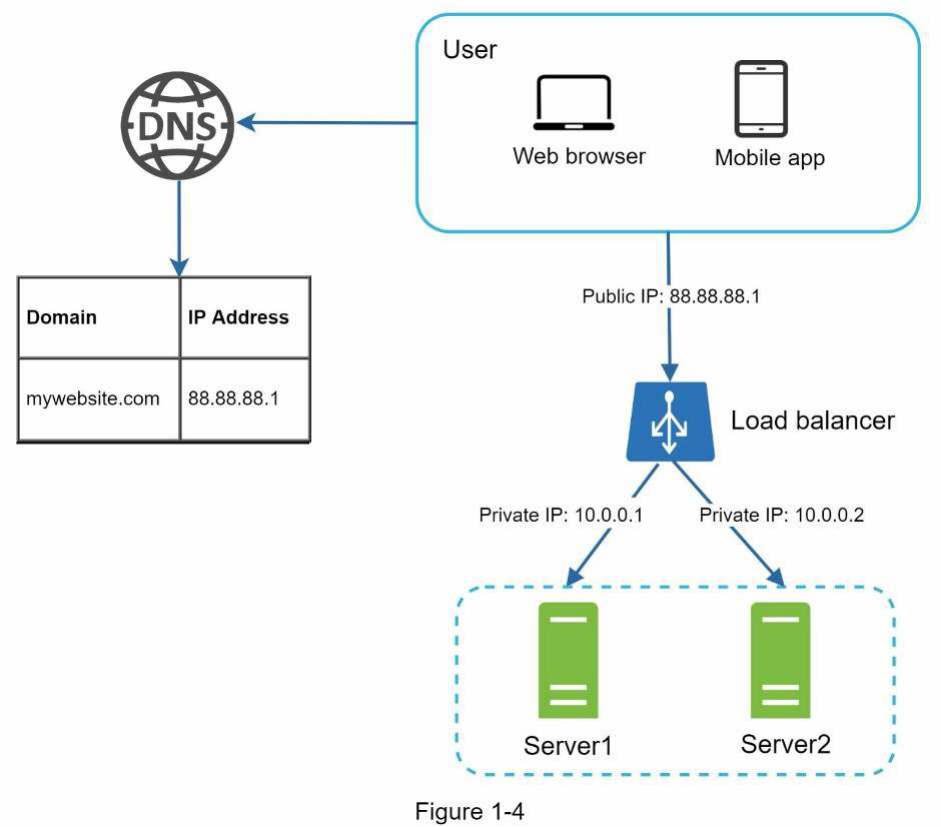
Hình 1-6 minh họa thiết kế hệ thống sau khi thêm load balancer và sao chép cơ sở dữ liệu.
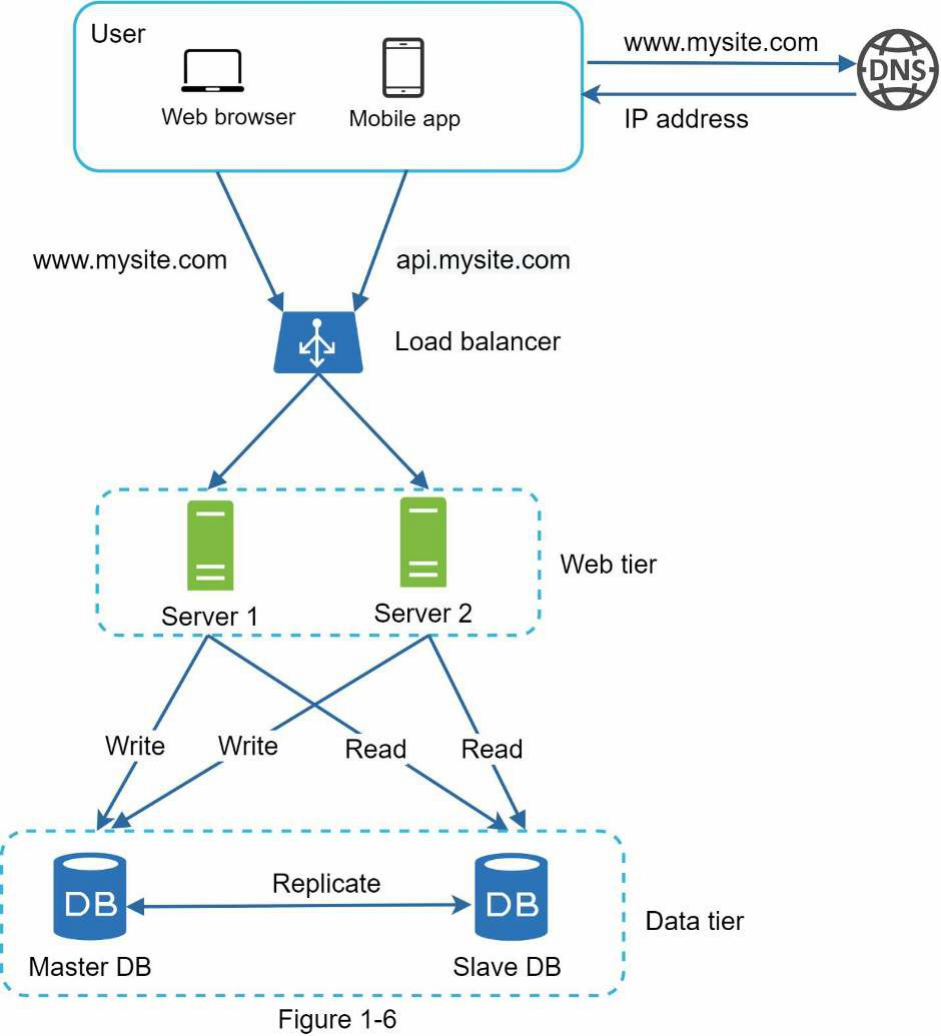
Hãy cùng xem xét thiết kế:
-
Một người dùng nhận địa chỉ IP của load balancer từ DNS.
-
Một người dùng kết nối với load balancer bằng địa chỉ IP này.
-
Yêu cầu HTTP được định tuyến đến Máy chủ 1 hoặc Máy chủ 2.
-
Một máy chủ web đọc dữ liệu người dùng từ một cơ sở dữ liệu slave.
-
Một máy chủ web định tuyến mọi thao tác sửa đổi dữ liệu đến cơ sở dữ liệu master. Điều này bao gồm các thao tác ghi, cập nhật và xóa.
Giờ đây, chúng ta đã có hiểu biết vững chắc về các tầng web và dữ liệu, đã đến lúc cải thiện thời gian tải/phản hồi. Điều này có thể được thực hiện bằng cách thêm một tầng cache (bộ nhớ đệm) và chuyển nội dung tĩnh (các tệp JavaScript/CSS/hình ảnh/video) sang mạng phân phối nội dung (CDN - Content Delivery Network).
Cache
Cache là một khu vực lưu trữ tạm thời, lưu trữ kết quả của các phản hồi tốn kém hoặc dữ liệu được truy cập thường xuyên trong bộ nhớ để các yêu cầu tiếp theo được phục vụ nhanh hơn. Như minh họa trong Hình 1-6, mỗi khi một trang web mới tải, một hoặc nhiều lệnh gọi cơ sở dữ liệu được thực thi để tìm nạp dữ liệu. Hiệu suất ứng dụng bị ảnh hưởng rất nhiều bởi việc gọi cơ sở dữ liệu lặp đi lặp lại. Cache có thể giảm thiểu vấn đề này.
Tầng cache
Tầng cache là một tầng lưu trữ dữ liệu tạm thời, nhanh hơn nhiều so với cơ sở dữ liệu. Lợi ích của việc có một tầng cache riêng biệt bao gồm hiệu suất hệ thống tốt hơn, khả năng giảm tải cho cơ sở dữ liệu và khả năng mở rộng tầng cache một cách độc lập. Hình 1-7 minh họa một thiết lập máy chủ cache khả thi:

Sau khi nhận được yêu cầu, một máy chủ web trước tiên kiểm tra xem cache có phản hồi khả dụng hay không. Nếu có, nó gửi dữ liệu trở lại client (máy khách). Nếu không, nó truy vấn cơ sở dữ liệu, lưu trữ phản hồi vào cache và gửi lại cho client. Chiến lược caching (lưu vào bộ nhớ đệm) này được gọi là read-through cache. Các chiến lược caching khác có sẵn tùy thuộc vào loại dữ liệu, kích thước và các mẫu truy cập. Một nghiên cứu trước đây giải thích cách các chiến lược caching khác nhau hoạt động [6].
Tương tác với các máy chủ cache rất đơn giản vì hầu hết các máy chủ cache đều cung cấp API cho các ngôn ngữ lập trình phổ biến. Đoạn mã sau đây minh họa các API Memcached điển hình:
Các cân nhắc khi sử dụng cache
Dưới đây là một vài cân nhắc khi sử dụng hệ thống cache:
-
Quyết định thời điểm sử dụng cache. Hãy cân nhắc sử dụng cache khi dữ liệu được đọc thường xuyên nhưng ít khi bị sửa đổi. Vì dữ liệu được lưu trong cache nằm trong bộ nhớ khả biến (volatile memory), một máy chủ cache không lý tưởng để lưu trữ dữ liệu lâu dài (persisting data). Ví dụ, nếu một máy chủ cache khởi động lại, tất cả dữ liệu trong bộ nhớ sẽ bị mất. Do đó, dữ liệu quan trọng nên được lưu trữ trong các kho dữ liệu bền vững (persistent data stores).
-
Chính sách hết hạn (Expiration policy). Việc triển khai một chính sách hết hạn là một thực hành tốt. Khi dữ liệu trong cache hết hạn, nó sẽ bị xóa khỏi cache. Khi không có chính sách hết hạn, dữ liệu trong cache sẽ được lưu trữ vĩnh viễn trong bộ nhớ. Không nên đặt thời gian hết hạn quá ngắn vì điều này sẽ khiến hệ thống phải tải lại dữ liệu từ cơ sở dữ liệu quá thường xuyên. Đồng thời, cũng không nên đặt thời gian hết hạn quá dài vì dữ liệu có thể trở nên lỗi thời (stale).
-
Tính nhất quán (Consistency): Điều này liên quan đến việc giữ cho kho dữ liệu và cache đồng bộ. Sự không nhất quán có thể xảy ra vì các thao tác sửa đổi dữ liệu trên kho dữ liệu và cache không nằm trong một giao dịch duy nhất. Khi mở rộng quy mô trên nhiều khu vực, việc duy trì tính nhất quán giữa
 kho dữ liệu và cache là một thách thức. Để biết thêm chi tiết, hãy tham khảo bài báo có tiêu đề “Scaling Memcache at Facebook” do Facebook xuất bản [7].
kho dữ liệu và cache là một thách thức. Để biết thêm chi tiết, hãy tham khảo bài báo có tiêu đề “Scaling Memcache at Facebook” do Facebook xuất bản [7].
-
Giảm thiểu lỗi: Một máy chủ cache duy nhất đại diện cho một điểm lỗi duy nhất tiềm ẩn (SPOF - Single Point of Failure), được định nghĩa trong Wikipedia như sau: “Một điểm lỗi duy nhất (SPOF) là một phần của hệ thống mà nếu nó bị lỗi, sẽ khiến toàn bộ hệ thống ngừng hoạt động” [8]. Do đó, nên sử dụng nhiều máy chủ cache trên các trung tâm dữ liệu khác nhau để tránh SPOF. Một cách tiếp cận được khuyến nghị khác là cấp phát quá mức (overprovision) bộ nhớ cần thiết theo một tỷ lệ phần trăm nhất định. Điều này cung cấp một vùng đệm khi mức sử dụng bộ nhớ tăng lên.
-
Chính sách loại bỏ (Eviction Policy): Khi cache đầy, bất kỳ yêu cầu nào để thêm các mục vào cache có thể khiến các mục hiện có bị xóa. Điều này được gọi là cache eviction (loại bỏ khỏi cache). Least-recently-used (LRU) là chính sách loại bỏ khỏi cache phổ biến nhất. Các chính sách loại bỏ khác, chẳng hạn như Least Frequently Used (LFU) hoặc First in First Out (FIFO), có thể được áp dụng để đáp ứng các trường hợp sử dụng khác nhau.
Content delivery network (CDN)
Một CDN là một mạng lưới các máy chủ phân tán về mặt địa lý, được sử dụng để phân phối nội dung tĩnh. Các máy chủ CDN lưu trữ nội dung tĩnh như hình ảnh, video, tệp CSS, JavaScript, v.v.
Caching nội dung động (dynamic content caching) là một khái niệm tương đối mới và nằm ngoài phạm vi của cuốn sách này. Nó cho phép lưu trữ các trang HTML dựa trên đường dẫn yêu cầu (request path), chuỗi truy vấn (query strings), cookie và tiêu đề yêu cầu (request headers). Để biết thêm về điều này, hãy tham khảo bài viết được đề cập trong tài liệu tham khảo [9]. Cuốn sách này tập trung vào cách sử dụng CDN để lưu trữ nội dung tĩnh.
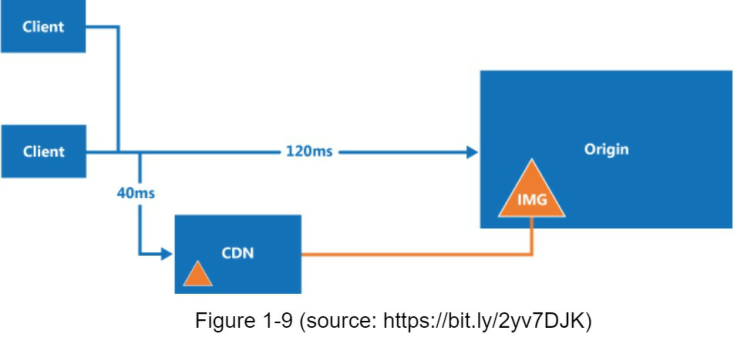
Đây là cách CDN hoạt động ở cấp độ cao: khi người dùng truy cập một trang web, máy chủ CDN gần người dùng nhất sẽ phân phối nội dung tĩnh. Một cách trực quan, người dùng càng ở xa máy chủ CDN thì trang web tải càng chậm. Ví dụ, nếu các máy chủ CDN đặt ở San Francisco, người dùng ở Los Angeles sẽ nhận được nội dung nhanh hơn người dùng ở Châu Âu. Hình 1-9 là một ví dụ tuyệt vời cho thấy cách CDN c�ải thiện thời gian tải.
Hình 1-10 minh họa quy trình làm việc của CDN.
-
Người dùng A cố gắng lấy
image.pngbằng cách sử dụng URL hình ảnh. Tên miền của URL được cung cấp bởi nhà cung cấp CDN. Hai URL hình ảnh sau đây là các ví dụ minh họa URL hình ảnh trông như thế nào trên các CDN của Amazon và Akamai:-
https://mysite.cloudfront.net/logo.jpg -
https://mysite.akamai.com/image-manager/img/logo.jpg
-
-
Nếu máy chủ CDN không có
image.pngtrong bộ nhớ đệm, máy chủ CDN sẽ yêu cầu tệp từ nguồn gốc (origin), có thể là một máy chủ web hoặc bộ lưu trữ trực tuyến như Amazon S3. -
Nguồn gốc trả về
image.pngcho máy chủ CDN, bao gồm tiêu đề HTTP tùy chọn Time-to-Live (TTL) mô tả thời gian hình ảnh được lưu trong bộ nhớ đệm.
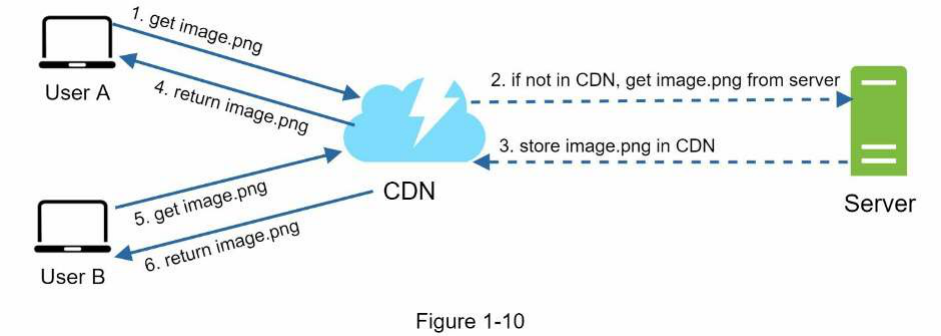 4. CDN lưu hình ảnh vào bộ nhớ đệm và trả về cho Người dùng A. Hình ảnh vẫn được lưu trong bộ nhớ đệm của CDN cho đến khi TTL hết hạn.
5. Người dùng B gửi yêu cầu để lấy cùng một hình ảnh.
6. Hình ảnh được trả về từ bộ nhớ đệm miễn là TTL chưa hết hạn.
4. CDN lưu hình ảnh vào bộ nhớ đệm và trả về cho Người dùng A. Hình ảnh vẫn được lưu trong bộ nhớ đệm của CDN cho đến khi TTL hết hạn.
5. Người dùng B gửi yêu cầu để lấy cùng một hình ảnh.
6. Hình ảnh được trả về từ bộ nhớ đệm miễn là TTL chưa hết hạn.
Những điểm c�ần cân nhắc khi sử dụng CDN
-
Chi phí: Các CDN được vận hành bởi các nhà cung cấp bên thứ ba, và chúng ta sẽ bị tính phí cho việc truyền dữ liệu vào và ra khỏi CDN. Việc lưu trữ các tài nguyên ít được sử dụng không mang lại lợi ích đáng kể, vì vậy chúng ta nên cân nhắc di chuyển chúng ra khỏi CDN.
-
Đặt thời gian hết hạn bộ nhớ đệm phù hợp: Đối với nội dung nhạy cảm về thời gian, việc đặt thời gian hết hạn bộ nhớ đệm (cache expiry time) là rất quan trọng. Thời gian hết hạn bộ nhớ đệm không nên quá dài cũng không nên quá ngắn. Nếu quá dài, nội dung có thể không còn mới. Nếu quá ngắn, nó có thể gây ra việc tải lại nội dung lặp đi lặp lại từ máy chủ gốc (origin servers) đến CDN.
-
CDN fallback (dự phòng CDN): Chúng ta nên xem xét cách trang web/ứng dụng của mình xử lý khi CDN gặp sự cố. Nếu có sự cố ngừng hoạt động tạm thời của CDN, các client (máy khách) phải có khả năng phát hiện vấn đề và yêu cầu tài nguyên từ nguồn gốc.
-
Hủy hiệu lực tệp (Invalidating files): Chúng ta có thể xóa một tệp khỏi CDN trước khi nó hết hạn bằng cách thực hiện một trong các thao tác sau:
-
Hủy hiệu lực đối tượng CDN bằng cách sử dụng các API do nhà cung cấp CDN cung cấp.
-
Sử dụng tính năng quản lý phiên bản đối tượng (object versioning) để phục vụ một phiên bản khác của đối tượng. Để quản lý phiên bản một đối tượng, chúng ta có thể thêm một tham số vào URL, chẳng hạn như số phiên bản. Ví dụ, số phiên bản 2 được thêm vào chuỗi truy vấn:
image.png?v=2.
-
Hình 1-11 cho thấy thiết kế sau khi CDN và bộ nhớ đệm được thêm vào.
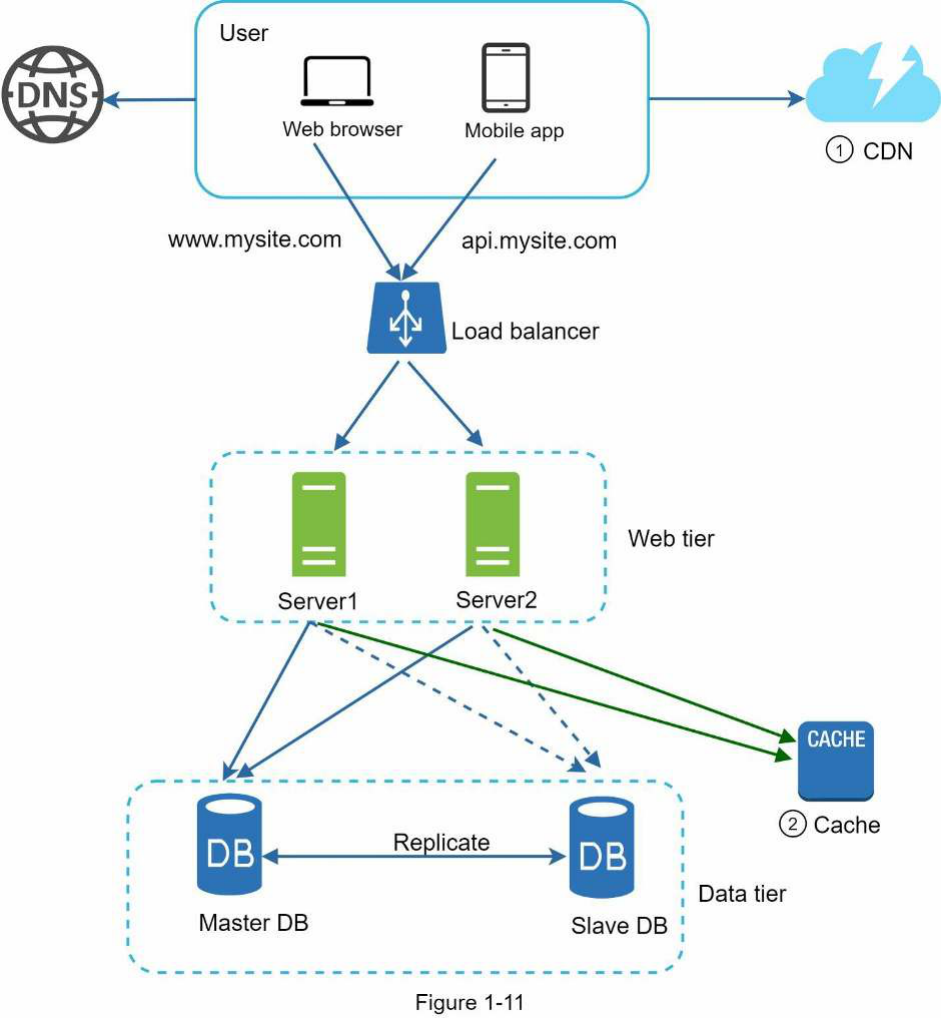
- Các tài nguyên tĩnh (JS, CSS, hình ảnh, v.v.) không còn được phục vụ bởi máy chủ web. Chúng được lấy từ CDN để có hiệu suất tốt hơn.
- Tải cơ sở dữ liệu được giảm bớt nhờ việc lưu trữ dữ liệu vào bộ nhớ đệm.
Tầng web phi trạng thái (Stateless web tier)
Bây giờ là lúc chúng ta xem xét việc mở rộng tầng web theo chiều ngang (horizontally). Để làm được điều này, chúng ta cần di chuyển trạng thái (ví dụ: dữ liệu phiên người dùng - user session data) ra khỏi tầng web. Một phương pháp hay là lưu trữ dữ liệu phiên trong bộ lưu trữ bền vững (persistent storage) như cơ sở dữ liệu quan hệ (relational database) hoặc NoSQL. Mỗi máy chủ web trong cụm có thể truy cập dữ liệu trạng thái từ các cơ sở dữ liệu. Đây được gọi là
Hàng đợi thông điệp (Message queue)
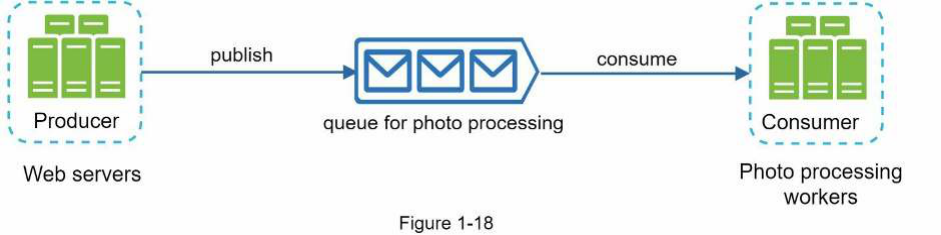
Hàng đợi thông điệp (message queue) là một thành phần bền vững, được lưu trữ trong bộ nhớ, hỗ trợ giao tiếp bất đồng bộ. Nó đóng vai trò như một bộ đệm và phân phối các yêu cầu bất đồng bộ. Kiến trúc cơ bản của một hàng đợi thông điệp rất đơn giản. Các dịch vụ đầu vào, được gọi là producer/publisher (bên sản xuất/phát hành), tạo thông điệp và gửi chúng đến hàng đợi thông điệp. Các dịch vụ hoặc máy chủ khác, được gọi là consumer/subscriber (bên tiêu thụ/đăng ký), kết nối với hàng đợi và thực hiện các hành động được định nghĩa bởi các thông điệp đó. Mô hình này được thể hiện trong Hình 1-17.
Việc tách rời (decoupling) khiến hàng đợi thông điệp trở thành một kiến trúc ưu tiên để xây dựng ứng dụng có khả năng mở rộng và đáng tin cậy. Với hàng đợi thông điệp, producer có thể gửi một thông điệp vào hàng đợi ngay cả khi consumer không sẵn sàng xử lý. Tương tự, consumer có thể đọc thông điệp từ hàng đợi ngay cả khi producer không khả dụng.
Hãy xem xét trường hợp sử dụng (use case) sau: ứng dụng của chúng ta hỗ trợ tùy chỉnh ảnh, bao gồm cắt, làm sắc nét, làm mờ, v.v. Các tác vụ tùy chỉnh này cần thời gian để hoàn thành. Trong Hình 1-18, các máy chủ web gửi (publish) các công việc xử lý ảnh vào hàng đợi thông điệp. Các worker xử lý ảnh sẽ lấy công việc từ hàng đợi thông điệp và thực hiện các tác vụ tùy chỉnh ảnh một cách bất đồng bộ. Producer và consumer có thể được mở rộng độc lập. Khi kích thước hàng đợi trở nên lớn, chúng ta có thể thêm nhiều worker hơn để giảm thời gian xử lý. Tuy nhiên, nếu hàng đợi trống trong phần lớn thời gian, số lượng worker có thể được giảm bớt.

Ghi nhật ký (Logging), số liệu (metrics) và tự động hóa (automation)
Khi làm việc với một trang web nhỏ chạy trên vài máy chủ, việc hỗ trợ ghi nhật ký (logging), số liệu (metrics) và tự động hóa (automation) là những thực hành tốt nhưng không phải là điều bắt buộc. Tuy nhiên, khi trang web của chúng ta đã phát triển để phục vụ một doanh nghiệp lớn, việc đầu tư vào các công cụ này là vô cùng cần thiết.
Ghi nhật ký (Logging): Việc giám sát nhật ký lỗi (error logs) rất quan trọng vì nó giúp xác định các lỗi và vấn đề trong hệ thống. Chúng ta có thể giám sát nhật ký lỗi ở cấp độ từng máy chủ hoặc sử dụng các công cụ để tổng hợp chúng vào một dịch vụ tập trung để dễ dàng tìm kiếm và xem.
Số liệu (Metrics): Việc thu thập các loại số liệu khác nhau giúp chúng ta có được thông tin chi tiết về kinh doanh (business insights) và hiểu được tình trạng sức khỏe của hệ thống. Một số số liệu hữu ích bao gồm:
-
Số liệu cấp máy chủ (Host level metrics): CPU, Memory, disk I/O, v.v.
-
Số liệu tổng hợp (Aggregated level metrics): ví dụ, hiệu suất của toàn bộ tầng cơ sở dữ liệu (database tier), tầng bộ đệm (cache tier), v.v.
-
Số liệu kinh doanh chính (Key business metrics): người dùng hoạt động hàng ngày (daily active users), tỷ lệ giữ chân (retention), doanh thu (revenue), v.v.
Tự động hóa (Automation): Khi một hệ thống trở nên lớn và phức tạp, chúng ta cần xây dựng hoặc tận dụng các công cụ tự động hóa để nâng cao năng suất. Continuous integration (CI) là một thực hành tốt, trong đó mỗi lần kiểm tra mã (code check-in) được xác minh thông qua tự động hóa, cho phép các nhóm phát hiện vấn đề sớm. Bên cạnh đó, việc tự động hóa quy trình xây dựng (build), kiểm thử (test), triển khai (deploy) của chúng ta, v.v. có thể cải thiện đáng kể năng suất của nhà phát triển.
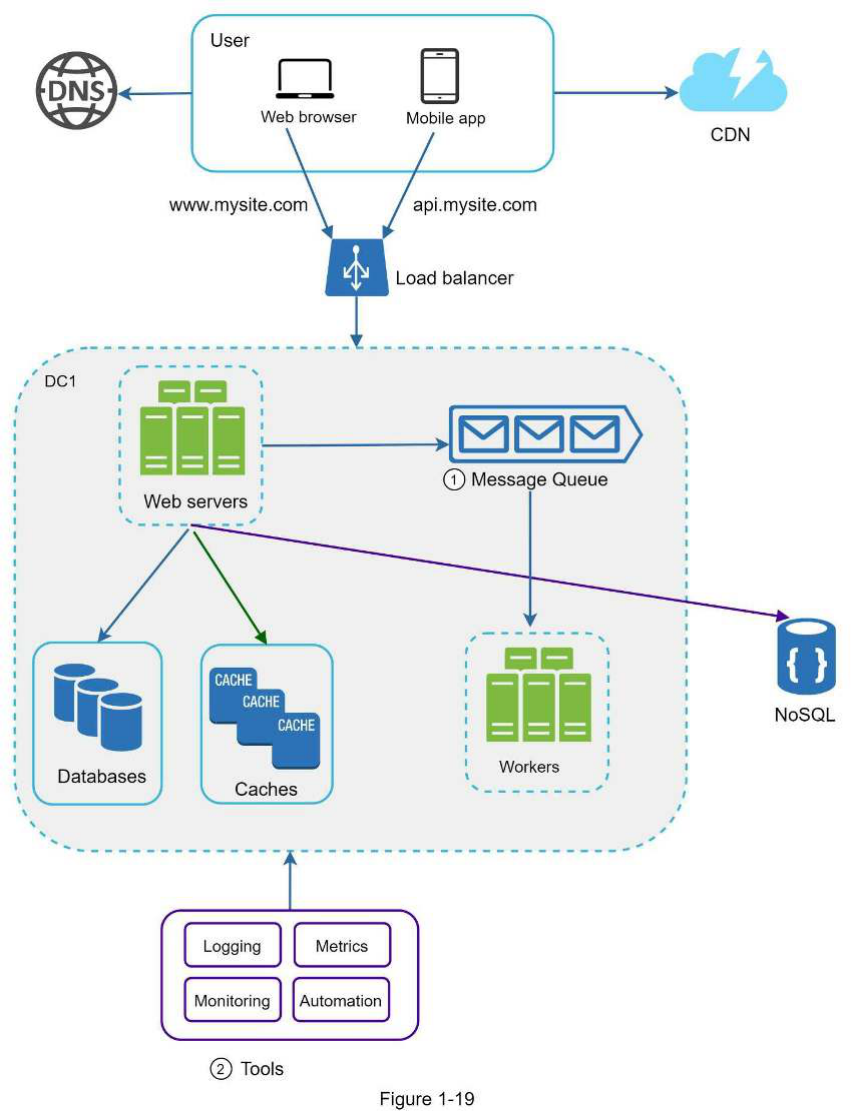
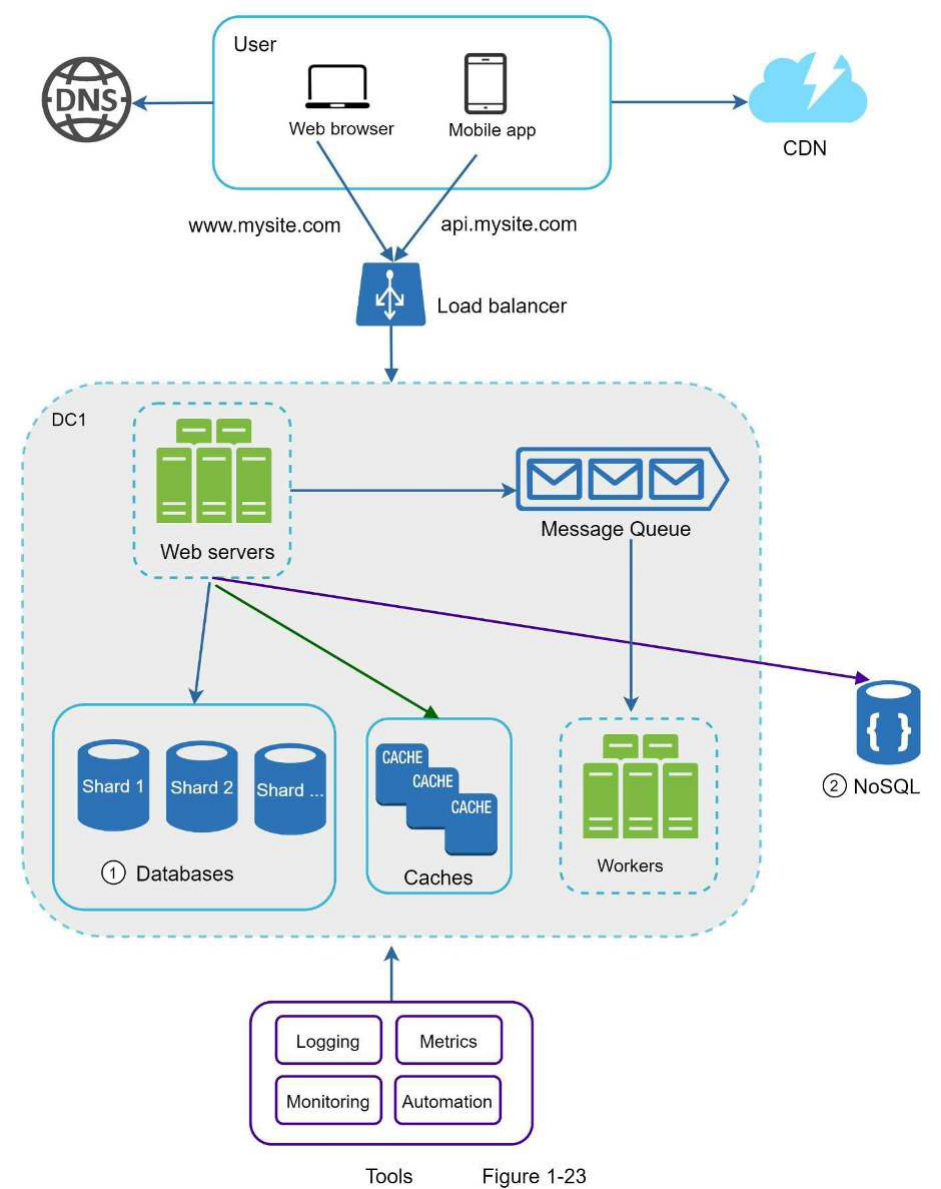
Thêm hàng đợi thông điệp và các công cụ khác Hình 1-19 thể hiện thiết kế đã được cập nhật. Do hạn chế về không gian, chỉ một trung tâm dữ liệu (data center) được hiển thị trong hình.
- Thiết kế bao gồm một hàng đợi thông điệp, giúp hệ thống trở nên ít phụ thuộc (loosely coupled) và có khả năng chống chịu lỗi (failure resilient) tốt hơn.
- Các công cụ ghi nhật ký (logging), giám sát (monitoring), số liệu (metrics) và tự động hóa (automation) cũng được tích hợp.
Khi dữ liệu tăng lên mỗi ngày, cơ sở dữ liệu của chúng ta ngày càng bị quá tải. Đã đến lúc mở rộng tầng dữ liệu (data tier).
Mở rộng cơ sở dữ liệu (Database scaling)
Có hai phương pháp chính để mở rộng cơ sở dữ liệu: mở rộng theo chiều dọc (vertical scaling) và mở rộng theo chiều ngang (horizontal scaling).
Mở rộng theo chiều dọc (Vertical scaling)
Mở rộng theo chiều dọc, còn được gọi là "scaling up", là việc mở rộng bằng cách thêm nhiều tài nguyên hơn (CPU, RAM, DISK, v.v.) vào một máy hiện có. Có một số máy chủ cơ sở dữ liệu mạnh mẽ. Theo Amazon Relational Database Service (RDS) [12], chúng ta có thể có một máy chủ cơ sở dữ liệu với 24 TB RAM. Loại máy chủ cơ sở dữ liệu mạnh mẽ này có thể lưu trữ và xử lý rất nhiều dữ liệu. Ví dụ, stackoverflow.com vào năm 2013 có hơn 10 triệu lượt khách truy cập duy nhất hàng tháng, nhưng nó chỉ có 1 cơ sở dữ liệu master [13]. Tuy nhiên, mở rộng theo chiều dọc đi kèm với một số nhược điểm nghiêm trọng:
-
Chúng ta có thể thêm nhiều CPU, RAM, v.v. vào máy chủ cơ sở dữ liệu của mình, nhưng có những giới hạn về phần cứng. Nếu chúng ta có một lượng lớn người dùng, một máy chủ duy nhất sẽ không đủ.
-
Rủi ro cao hơn về điểm lỗi duy nhất (single point of failures).
-
Chi phí tổng thể của mở rộng theo chiều dọc cao. Các máy chủ mạnh mẽ đắt hơn nhiều.
Mở rộng theo chiều ngang (Horizontal scaling)
Mở rộng theo chiều ngang, còn được gọi là sharding (tiếng Anh: sharding), là thực hành thêm nhiều máy chủ hơn. Hình 1-20 so sánh mở rộng theo chiều dọc với mở rộng theo chiều ngang.
Sharding phân tách các cơ sở dữ liệu lớn thành các phần nhỏ hơn, dễ quản lý hơn được gọi là shard. Mỗi shard chia sẻ cùng một lược đồ (schema), mặc dù dữ liệu thực tế trên mỗi shard là duy nhất cho shard đó.
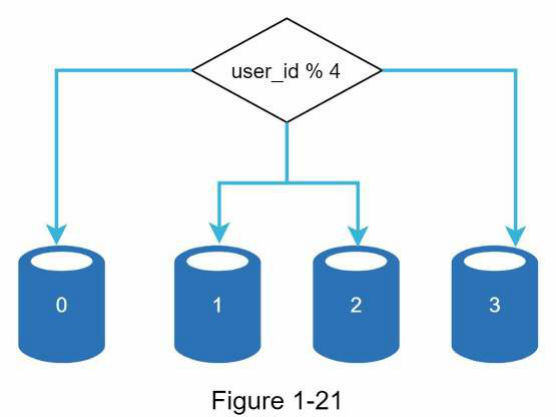
Hình 1-21 cho thấy một ví dụ về các cơ sở dữ liệu được sharding. Dữ liệu người dùng được phân bổ cho một máy chủ cơ sở dữ liệu dựa trên ID người dùng. Bất cứ khi nào chúng ta truy cập dữ liệu, một hàm băm (hash function) sẽ được sử dụng để tìm shard tương ứng. Trong ví dụ của chúng ta, user_id % 4 được sử dụng làm hàm băm. Nếu kết quả
 bằng 0, shard 0 được sử dụng để lưu trữ và truy xuất dữ liệu. Nếu kết quả bằng 1, shard 1 được sử dụng. Logic tương tự áp dụng cho các shard khác.
bằng 0, shard 0 được sử dụng để lưu trữ và truy xuất dữ liệu. Nếu kết quả bằng 1, shard 1 được sử dụng. Logic tương tự áp dụng cho các shard khác.
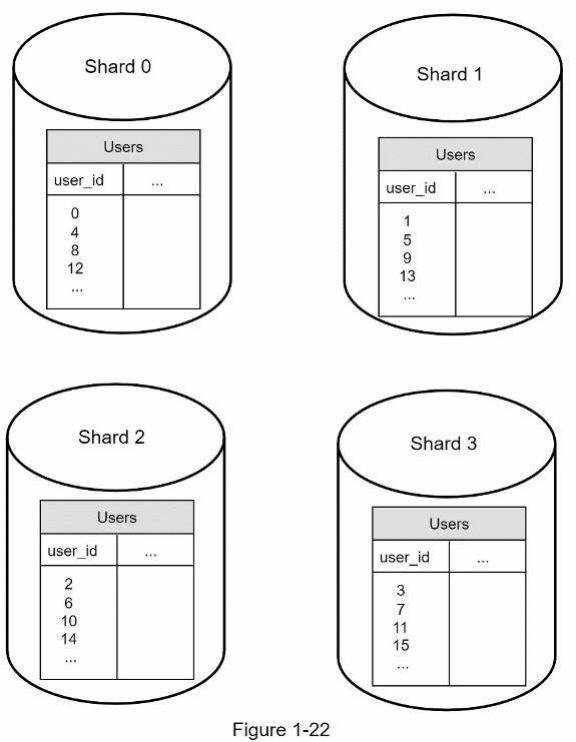
Hình 1-22 cho thấy bảng người dùng trong các cơ sở dữ liệu được sharding.
Yếu tố quan trọng nhất cần xem xét khi triển khai chiến lược sharding là lựa chọn khóa sharding (sharding key). Khóa sharding (còn được gọi là partition key) bao gồm một hoặc nhiều cột xác định cách dữ liệu được phân phối. Như thể hiện trong Hình 1-22, “user_id” là khóa sharding. Khóa sharding cho phép chúng ta truy xuất và sửa đổi dữ liệu một cách hiệu quả bằng cách định tuyến các truy vấn cơ sở dữ liệu đến đúng cơ sở dữ liệu. Khi chọn khóa sharding, một trong những tiêu chí quan trọng nhất
 là chọn một khóa có thể phân phối dữ liệu đồng đều.
là chọn một khóa có thể phân phối dữ liệu đồng đều.
Sharding là một kỹ thuật tuyệt vời để mở rộng cơ sở dữ liệu nhưng nó còn lâu mới là một giải pháp hoàn hảo. Nó mang lại sự phức tạp và những thách thức mới cho hệ thống:
Resharding dữ liệu (Resharding data): Resharding dữ liệu là cần thiết khi 1) một shard duy nhất không thể chứa thêm dữ liệu do tốc độ tăng trưởng nhanh. 2) Một số shard nhất định có thể gặp tình trạng cạn kiệt shard (shard exhaustion) nhanh hơn các shard khác do phân phối dữ liệu không đồng đều. Khi tình trạng cạn kiệt shard xảy ra, nó yêu cầu cập nhật hàm sharding và di chuyển dữ liệu. Consistent hashing (tiếng Anh: Consistent hashing), sẽ được thảo luận trong Chương 5, là một kỹ thuật thường được sử dụng để giải quyết vấn đề này.
Vấn đề người nổi tiếng (Celebrity problem): Đây còn được gọi là vấn đề khóa điểm nóng (hotspot key problem). Việc truy cập quá mức vào một shard cụ thể có thể gây quá tải máy chủ. Hãy tưởng tượng dữ liệu của Katy Perry, Justin Bieber và Lady Gaga đều nằm trên cùng một shard. Đối với các ứng dụng xã hội, shard đó sẽ bị quá tải với các thao tác đọc. Để giải quyết vấn đề này, chúng ta có thể cần phân bổ một shard cho mỗi người nổi tiếng. Mỗi shard thậm chí có thể yêu cầu phân vùng (partition) thêm.
Join và khử chuẩn hóa (De-normalization): Một khi cơ sở dữ liệu đã được sharding trên nhiều máy chủ, việc thực hiện các thao tác join (kết nối) giữa các shard cơ sở dữ liệu là rất khó. Một giải pháp thay thế phổ biến là khử chuẩn hóa (de-normalize) cơ sở dữ liệu để c�ác truy vấn có thể được thực hiện trong một bảng duy nhất.
Trong Hình 1-23, chúng ta sharding các cơ sở dữ liệu để hỗ trợ lưu lượng dữ liệu tăng nhanh. Đồng thời, một số chức năng phi quan hệ (non-relational functionalities) được chuyển sang kho dữ liệu NoSQL để giảm tải cho cơ sở dữ liệu. Đây là một bài viết bao gồm nhiều trường hợp sử dụng của NoSQL [14].
...trong một bảng duy nhất.
Trong Hình 1-23, chúng ta phân mảnh cơ sở dữ liệu để hỗ trợ lưu lượng dữ liệu tăng nhanh chóng. Đồng thời, một số chức năng phi quan hệ được chuyển sang kho dữ liệu NoSQL để giảm tải cho cơ sở dữ liệu. Dưới đây là một bài viết bao gồm nhiều trường hợp sử dụng của NoSQL [14].
Hàng triệu người dùng và hơn thế nữa
Mở rộng quy mô một hệ thống là một quá trình lặp đi lặp lại. Áp dụng lặp lại những gì chúng ta đã học trong chương này có thể giúp chúng ta tiến xa. Cần có thêm Fine-tuning và các chiến lược mới để mở r��ộng quy mô vượt ra ngoài hàng triệu người dùng. Ví dụ, bạn có thể cần tối ưu hóa hệ thống của mình và phân tách hệ thống thành các dịch vụ nhỏ hơn nữa. Tất cả các kỹ thuật đã học trong chương này sẽ cung cấp một nền tảng tốt để giải quyết các thách thức mới. Để kết thúc chương này, chúng ta sẽ tóm tắt cách chúng ta mở rộng quy mô hệ thống để hỗ trợ hàng triệu người dùng:
-
Giữ tầng web không trạng thái (stateless)
-
Xây dựng dự phòng (redundancy) ở mọi tầng
-
Cache dữ liệu nhiều nhất có thể
-
Hỗ trợ nhiều trung tâm dữ liệu
-
Lưu trữ tài nguyên tĩnh (static assets) trong CDN
-
Mở rộng quy mô tầng dữ liệu bằng cách phân mảnh (sharding)
-
Chia các tầng thành các dịch vụ riêng lẻ
-
Giám sát hệ thống và sử dụng các công cụ tự động hóa
Chúc mừng bạn đã đi được đến đây! Bây giờ hãy tự thưởng cho mình một lời khen. Làm tốt lắm!
Tài liệu tham khảo
[1] Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[2] Bạn có nên vượt ra ngoài cơ sở dữ liệu quan hệ?: https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases
[3] Nhân bản (Replication): https://en.wikipedia.org/wiki/Replication_(computing)
[4] Nhân bản đa chủ (Multi-master replication): https://en.wikipedia.org/wiki/Multi-master_replication
[5] Nhân bản cụm NDB: Nhân bản đa chủ và nhân bản vòng tròn: https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-replication-multi-master.html
[6] Các chiến lược Cache và cách chọn chiến lược phù hợp: https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
[7] R. Nishtala, "Facebook, Scaling Memcache at," 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’13).
[8] Điểm lỗi duy nhất (Single point of failure): https://en.wikipedia.org/wiki/Single_point_of_failure
[9] Phân phối nội dung động Amazon CloudFront: https://aws.amazon.com/cloudfront/dynamic-content/
[10] Cấu hình Sticky Sessions cho Classic Load Balancer của bạn: https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
[11] Active-Active cho khả năng phục hồi đa vùng: https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
[12] Các phiên bản Amazon EC2 bộ nhớ cao: https://aws.amazon.com/ec2/instance-types/high-memory/
[13] Những gì cần thiết để vận hành Stack Overflow: http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow
[14] Bạn thực sự đang sử dụng NoSQL để làm gì?: http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosqlfor.html
Made by Anh Tu - Share to be share