[System design interview] CHƯƠNG 5: THIẾT KẾ CONSISTENT HASHING

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
Để đạt được khả năng mở rộng theo chiều ngang (horizontal scaling), việc phân phối các yêu cầu/dữ liệu một cách hiệu quả và đồng đều trên các máy chủ là rất quan trọng. Consistent hashing là một kỹ thuật thường được sử dụng để đạt được mục tiêu này. Nhưng trước tiên, chúng ta hãy cùng tìm hiểu sâu về vấn đề.
Vấn đề băm lại (rehashing)
Nếu chúng ta có n máy chủ cache, một cách phổ biến để cân bằng tải là sử dụng phương pháp băm (hash method) sau:
serverIndex = hash(key) % N, trong đó N là kích thước của nhóm máy chủ (server pool).
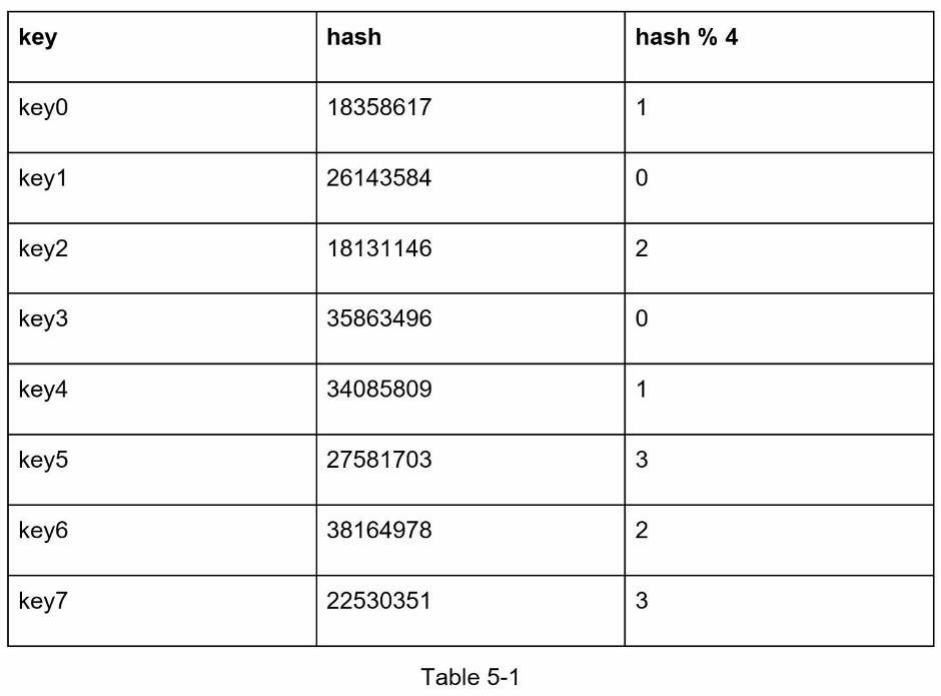
Chúng ta hãy sử dụng một ví dụ để minh họa cách nó hoạt động. Như được hiển thị trong Bảng 5-1, chúng ta có 4 máy chủ và 8 khóa chuỗi (string key) cùng với các giá trị băm của chúng.
Để tìm máy chủ nơi một khóa được lưu trữ, chúng ta thực hiện phép toán modulo f(key) % 4. Ví dụ, hash(key0) % 4 = 1 có nghĩa là một client phải liên hệ với máy chủ 1 để lấy dữ liệu đã được cache. Hình 5-1 cho thấy sự phân phối các khóa dựa trên Bảng 5-1.
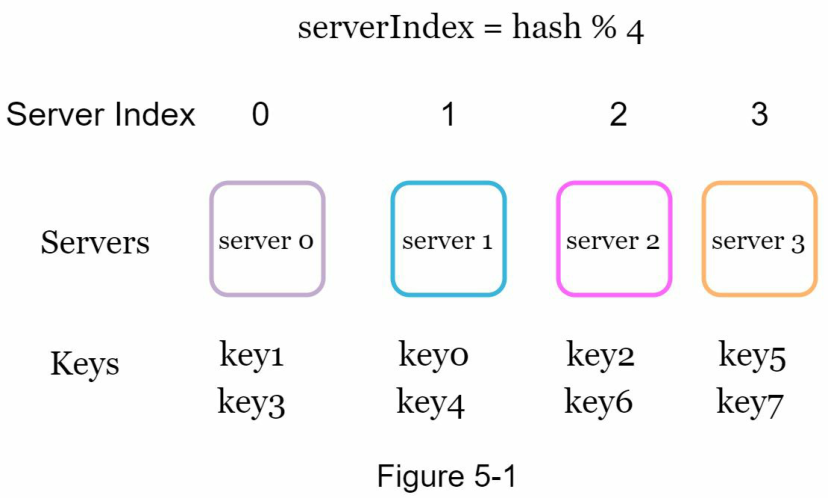
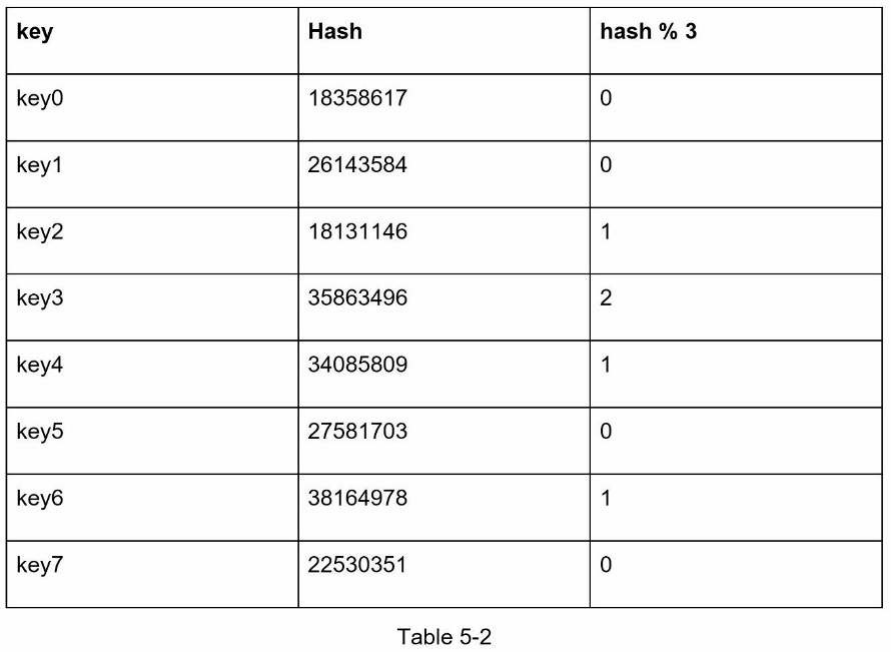
Cách tiếp cận này hoạt động tốt khi kích thước của nhóm máy chủ là cố định và dữ liệu được phân phối đồng đều. Tuy nhiên, các vấn đề phát sinh khi máy chủ mới được thêm vào hoặc các máy chủ hiện có bị loại bỏ. Ví dụ, nếu máy chủ 1 ngừng hoạt động, kích thước của nhóm máy chủ trở thành 3. Sử dụng cùng một hàm băm (hash function), chúng ta nhận được cùng một giá trị băm cho một khóa. Nhưng việc áp dụng phép toán modulo sẽ cho chúng ta các chỉ mục máy chủ khác nhau vì số lượng máy chủ đã giảm đi 1. Chúng ta nhận được kết quả như hiển thị trong Bảng 5-2 bằng cách áp dụng hash % 3:
Hình 5-2 cho thấy sự phân phối khóa mới dựa trên Bảng 5-2.
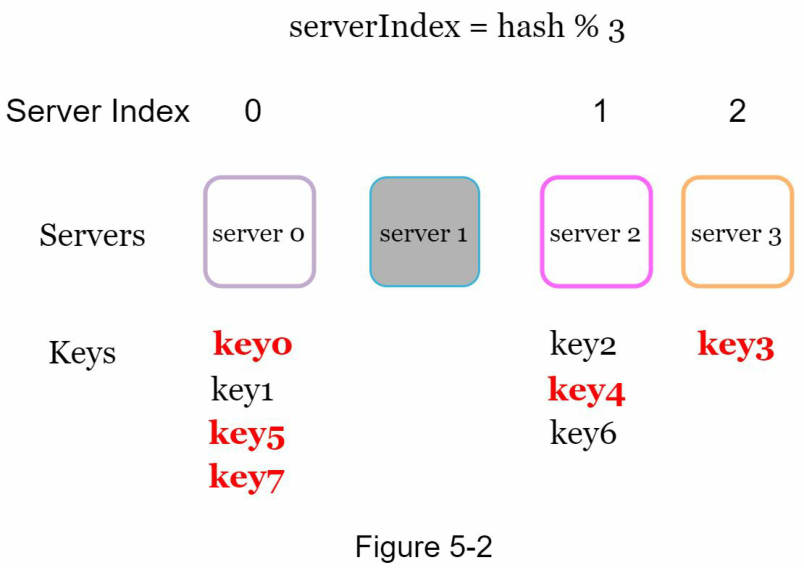
Như được hiển thị trong Hình 5-2, hầu hết các khóa đều được phân phối lại, chứ không chỉ những khóa ban đầu được lưu trữ trên máy chủ ngừng hoạt động (máy chủ 1). Điều này có nghĩa là khi máy chủ 1 ngừng hoạt động, hầu hết các client cache sẽ kết nối đến các máy chủ sai để lấy dữ liệu. Điều này gây ra một "cơn bão" các lỗi cache (cache miss). Consistent hashing là một kỹ thuật hiệu quả để giảm thiểu vấn đề này.
Consistent hashing
Trích dẫn từ Wikipedia: "Consistent hashing là một loại băm đặc biệt, sao cho khi một bảng băm (hash table) được thay đổi kích thước và consistent hashing được sử dụng, trung bình chỉ k/n khóa cần được ánh xạ lại, trong đó k là số lượng khóa và n là số lượng khe (slot). Ngược lại, trong hầu hết các bảng băm truyền thống, việc thay đổi số lượng khe mảng (array slot) khiến gần như tất cả các khóa phải được ánh xạ lại [1]".
Không gian băm và vòng băm
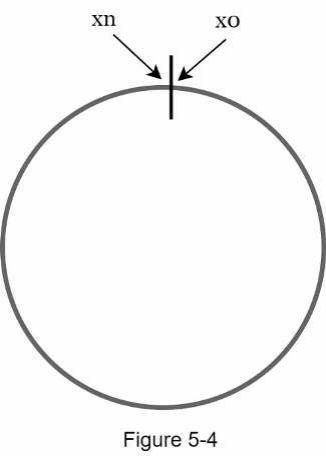
Bây giờ chúng ta đã hiểu định nghĩa của consistent hashing, hãy cùng tìm hiểu cách nó hoạt động. Giả sử SHA-1 được sử dụng làm hàm băm f, và phạm vi đầu ra của hàm băm là: x0, x1, x2, x3, …, xn. Trong mật mã học (cryptography), không gian băm của SHA-1 trải dài từ 0 đến 2^160 - 1. Điều đó có nghĩa là x0 tương ứng với 0, xn tương ứng với 2^160 – 1, và tất cả các giá trị băm khác ở giữa nằm trong khoảng từ 0 đến 2^160 - 1. Hình 5-3 cho thấy không gian băm.
Bằng cách nối hai đầu lại, chúng ta có được một vòng băm như được hiển thị trong Hình 5-4:
Băm máy chủ
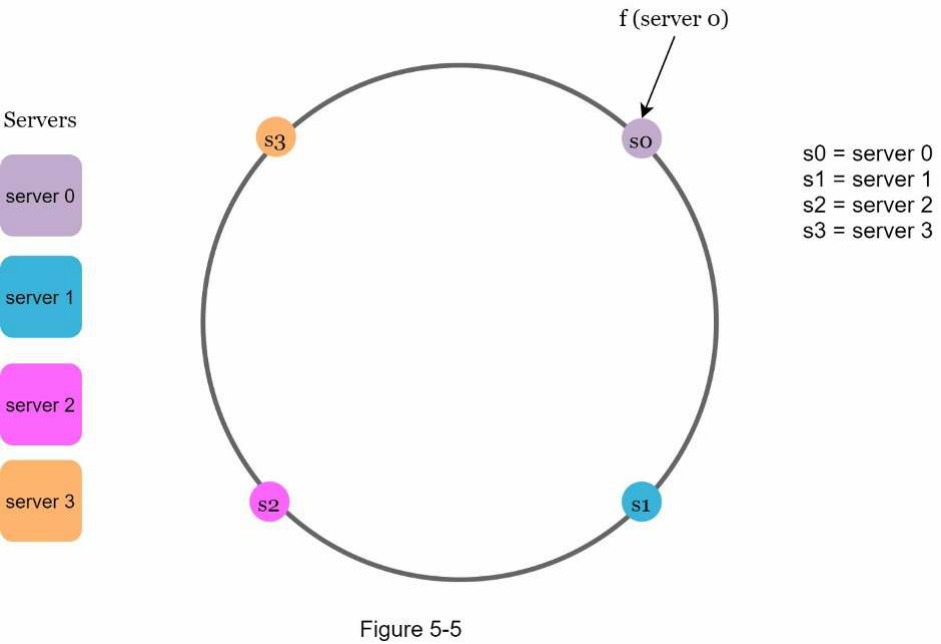
Sử dụng cùng hàm băm f, chúng ta ánh xạ các máy chủ dựa trên địa chỉ IP hoặc tên máy chủ lên vòng. Hình 5-5 cho thấy 4 máy chủ được ánh xạ trên vòng băm.

Băm khóa
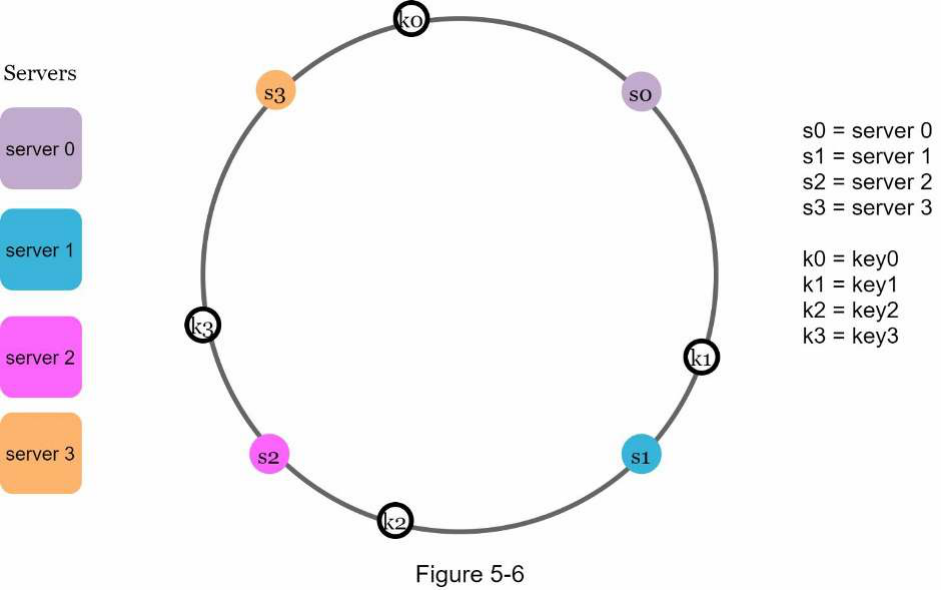
Một điều đáng nói là hàm băm được sử dụng ở đây khác với hàm băm trong "vấn đề băm lại", và không có phép toán modulo. Như được hiển thị trong Hình 5-6, 4 khóa cache (key0, key1, key2 và key3) được băm lên vòng băm.
Tra cứu máy chủ
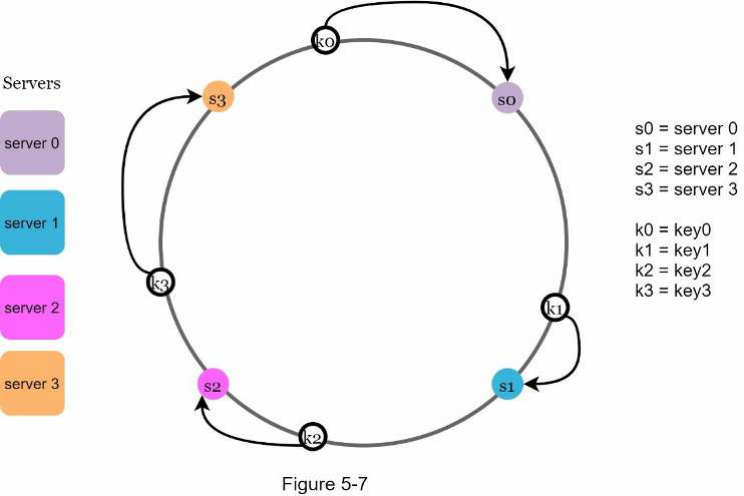
 Để xác định một khóa được lưu trữ trên máy chủ nào, chúng ta đi theo chiều kim đồng hồ từ vị trí của khóa trên vòng cho đến khi tìm thấy một máy chủ. Hình 5-7 giải thích quá trình này. Đi theo chiều kim đồng hồ, key0 được lưu trữ trên server 0; key1 được lưu trữ trên server 1; key2 được lưu trữ trên server 2 và key3 được lưu trữ trên server 3.
Để xác định một khóa được lưu trữ trên máy chủ nào, chúng ta đi theo chiều kim đồng hồ từ vị trí của khóa trên vòng cho đến khi tìm thấy một máy chủ. Hình 5-7 giải thích quá trình này. Đi theo chiều kim đồng hồ, key0 được lưu trữ trên server 0; key1 được lưu trữ trên server 1; key2 được lưu trữ trên server 2 và key3 được lưu trữ trên server 3.
Thêm máy chủ
Sử dụng logic đã mô tả ở trên, việc thêm một máy chủ mới sẽ chỉ yêu cầu phân phối lại một phần nhỏ các khóa.
Trong Hình 5-8, sau khi một server 4 mới được thêm vào, chỉ key0 cần được phân phối lại. k1, k2 và k3 vẫn nằm trên cùng các máy chủ. Chúng ta hãy xem xét kỹ hơn logic này. Trước khi server 4 được thêm vào, key0 được lưu trữ trên server 0. Bây giờ, key0 sẽ được lưu trữ trên server 4 vì server 4 là máy chủ đầu tiên nó gặp khi đi theo chiều kim đồng hồ từ vị trí của key0 trên vòng. Các khóa khác không được phân phối lại dựa trên thuật toán consistent hashing.
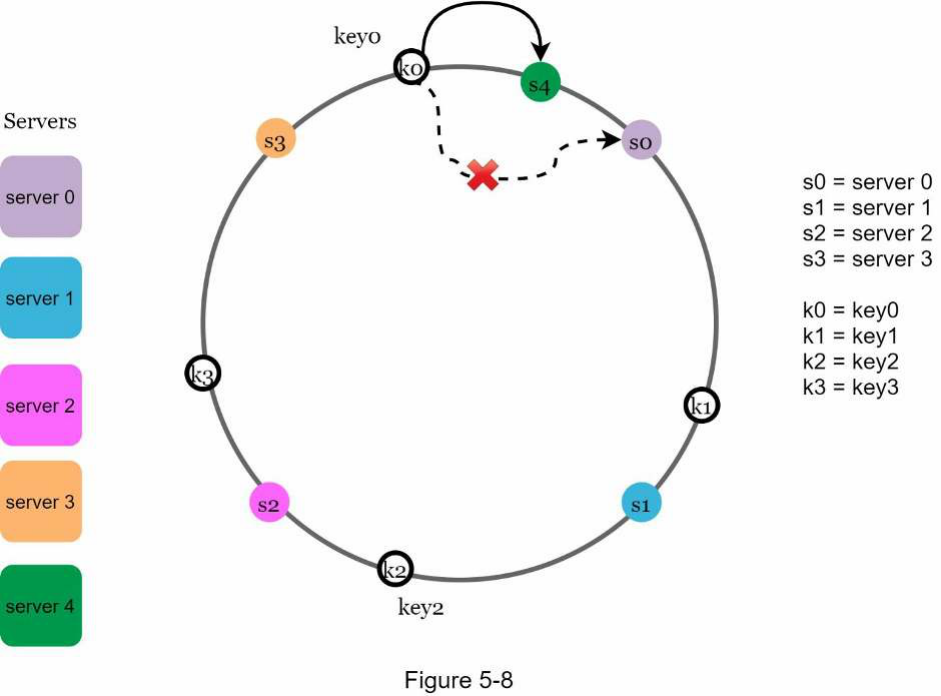
Xóa máy chủ
Khi một máy chủ bị loại bỏ, chỉ một phần nhỏ các khóa yêu cầu phân phối lại với consistent hashing. Trong Hình 5-9, khi server 1 bị loại bỏ, chỉ key1 phải được ánh xạ lại tới server 2. Các khóa còn lại không bị ảnh hưởng.
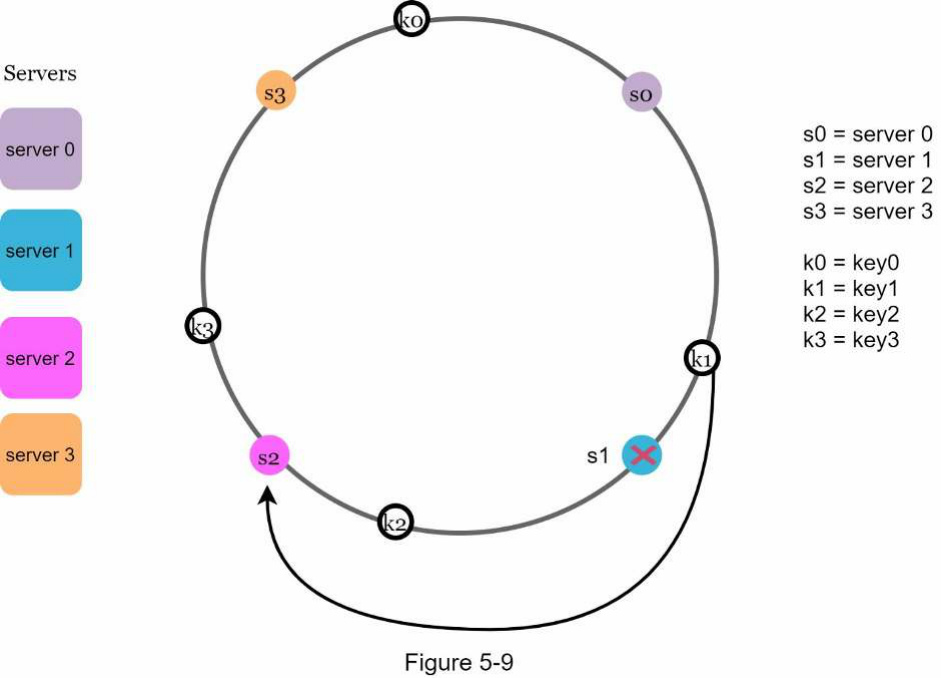
Hai vấn đề trong cách tiếp cận cơ bản
Thuật toán consistent hashing được giới
Tìm các khóa bị ảnh hưởng
Khi một máy chủ được thêm hoặc xóa, một phần dữ liệu cần được phân phối lại. Làm thế nào chúng ta có thể tìm thấy phạm vi bị ảnh hưởng để phân phối lại các khóa?
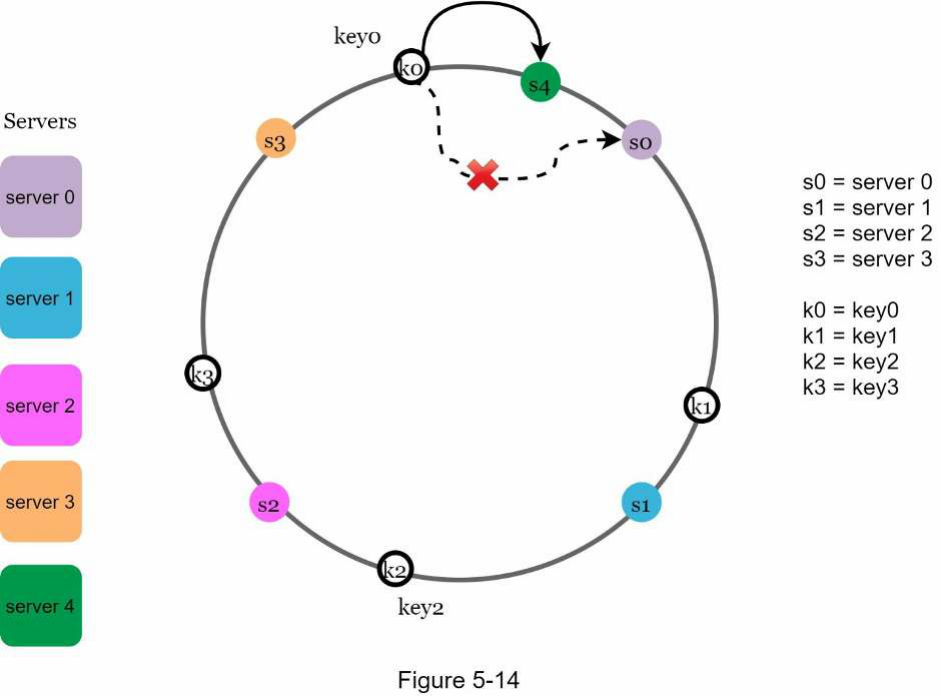
Trong Hình 5-14, máy chủ 4 được thêm vào vòng tròn. Phạm vi bị ảnh hưởng bắt đầu từ s4 (nút mới được thêm vào) và di chuyển ngược chiều kim đồng hồ quanh vòng tròn cho đến khi tìm thấy một máy chủ ( s3 ). Do đó, các khóa nằm giữa s3 và s4 cần được phân phối lại cho s4 .
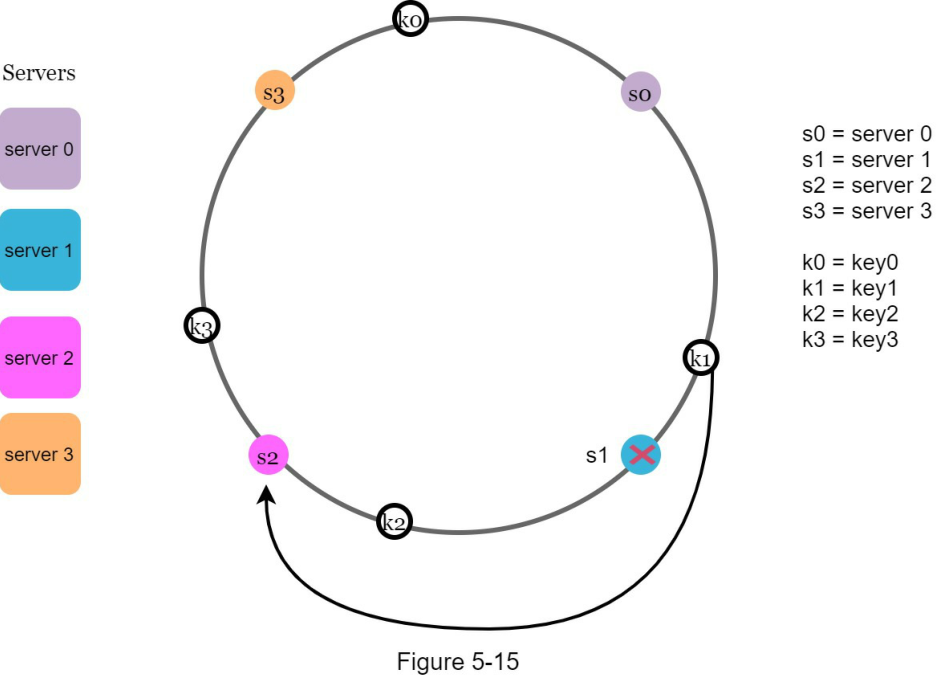
Khi một máy chủ ( s1 ) bị xóa như trong Hình 5-15, phạm vi bị ảnh hưởng bắt đầu từ s1 (nút bị xóa) và di chuyển ngược chiều kim đồng hồ quanh vòng tròn cho đến khi tìm thấy một máy chủ ( s0 ). Do đó, các khóa nằm giữa s0 và s1 phải được phân phối lại cho s2 .
Tổng kết
Trong chương này, chúng ta đã có một cuộc thảo luận chuyên sâu về hashing nhất quán, bao gồm lý do cần thiết và cách hoạt động của nó. Lợi ích của hashing nhất quán bao gồm:
-
Số lượng khóa cần phân phối lại được giảm thiểu khi máy chủ được thêm hoặc xóa.
-
Dễ dàng mở rộng theo chiều ngang vì dữ liệu được phân phối đồng đều hơn.
-
Giảm thiểu vấn đề khóa nóng (hotspot key problem). Truy cập quá mức vào một shard cụ thể có thể gây quá tải máy chủ. Hãy tưởng tượng dữ liệu của Katy Perry, Justin Bieber và Lady Gaga đều nằm trên cùng một shard. Hashing nhất quán giúp giảm thiểu vấn đề này bằng cách phân phối dữ liệu đồng đều hơn.
Hashing nhất quán được sử dụng rộng rãi trong các hệ thống thực tế, bao gồm một số hệ thống đáng chú ý:
-
Thành phần phân vùng của cơ sở dữ liệu Dynamo của Amazon [3]
-
Phân vùng dữ liệu trên toàn cụm trong Apache Cassandra [4]
-
Ứng dụng trò chuyện Discord [5]
-
Mạng phân phối nội dung Akamai [6]
-
Bộ cân bằng tải mạng Maglev [7]
Chúc mừng bạn đã đi được đến đây! Bây giờ hãy tự thưởng cho mình một lời khen. Làm tốt lắm!
Tài liệu tham khảo
[1] Hashing nhất quán: https://en.wikipedia.org/wiki/Consistent_hashing
[2] Hashing nhất quán: https://tom-e-white.com/2007/11/consistent-hashing.html
[3] Dynamo: Kho lưu trữ khóa-giá trị có tính sẵn sàng cao của Amazon: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[4] Cassandra - Hệ thống lưu trữ có cấu trúc phi tập trung: http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
[5] Cách Discord mở rộng Elixir để phục vụ 5.000.000 người dùng đồng thời: https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
[6] CS168: Hộp công cụ thuật toán hiện đại Bài giảng #1: Giới thiệu và Hashing nhất quán: http://theory.stanford.edu/~tim/s16/l/l1.pdf
[7] Maglev: Bộ cân bằng tải mạng phần mềm nhanh và đáng tin cậy: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44824.pdf
Made by Anh Tu - Share to be share