[System design interview] CHƯƠNG 4: THIẾT KẾ MỘT RATE LIMITER

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
CHƯƠNG 4: THIẾT KẾ MỘT RATE LIMITER
Trong một hệ thống mạng, một rate limiter được sử dụng để kiểm soát tốc độ lưu lượng truy cập do client hoặc một dịch vụ gửi đi. Trong thế giới HTTP, một rate limiter giới hạn số lượng yêu cầu của client được phép gửi trong một khoảng thời gian xác định. Nếu số lượng yêu cầu API vượt quá ngưỡng được định nghĩa bởi rate limiter, tất cả các cuộc gọi vượt mức sẽ bị chặn. Dưới đây là một vài ví dụ:
-
Một người dùng không thể viết quá 2 bài đăng mỗi giây.
-
Bạn có thể tạo tối đa 10 tài khoản mỗi ngày từ cùng một địa chỉ IP.
-
Bạn không thể nhận thưởng quá 5 lần mỗi tuần từ cùng một thiết bị.
Trong chương này, chúng ta được yêu cầu thiết kế một rate limiter. Trước khi bắt đầu thiết kế, chúng ta hãy cùng xem xét những lợi ích của việc sử dụng một API rate limiter:
-
Ngăn chặn tình trạng cạn kiệt tài nguyên do tấn công Denial of Service (DoS) [1]. Hầu hết các API được công bố bởi các công ty công nghệ lớn đều áp dụng một hình thức giới hạn tốc độ nào đó. Ví dụ, Twitter giới hạn số lượng tweet là 300 mỗi 3 giờ [2]. Các API của Google Docs có giới hạn mặc định sau: 300 yêu cầu đọc mỗi người dùng mỗi 60 giây [3]. Một rate limiter ngăn chặn các cuộc tấn công DoS, dù là cố ý hay vô ý, bằng cách chặn các cuộc gọi vượt mức.
-
Giảm chi phí. Việc giới hạn các yêu cầu vượt mức có nghĩa là cần ít máy chủ hơn và phân bổ nhiều tài nguyên hơn cho các API có độ ưu tiên cao. Giới hạn tốc độ cực kỳ quan trọng đối với các công ty sử dụng các API của bên thứ ba phải trả phí. Ví dụ, chúng ta bị tính phí trên cơ sở mỗi cuộc gọi đối với các API bên ngoài sau: kiểm tra tín dụng, thực hiện thanh toán, truy xuất hồ sơ sức khỏe, v.v. Giới hạn số lượng cuộc gọi là điều cần thiết để giảm chi phí.
-
Ngăn chặn máy chủ bị quá tải. Để giảm tải máy chủ, một rate limiter được sử dụng để lọc bỏ các yêu cầu vượt mức do bot hoặc hành vi sai trái của người dùng gây ra.
Bước 1 - Hiểu rõ vấn đề và xác định phạm vi thiết kế
Giới hạn tốc độ có thể được triển khai bằng nhiều thuật toán khác nhau, mỗi thuật toán đều có ưu và nhược điểm riêng. Các tương tác giữa người phỏng vấn và ứng viên giúp làm rõ loại rate limiter mà chúng ta đang cố gắng xây dựng.
Ứng viên : Chúng ta sẽ thiết kế loại rate limiter nào? Đó là rate limiter phía client hay rate limiter API phía server? Người phỏng vấn : Câu hỏi hay. Chúng ta tập trung vào rate limiter API phía server.
Ứng viên : Rate limiter có điều tiết các yêu cầu API dựa trên IP, ID người dùng hay các thuộc tính khác không? Người phỏng vấn : Rate limiter phải đủ linh hoạt để hỗ trợ các bộ quy tắc điều tiết khác nhau.
Ứng viên : Quy mô của hệ thống là bao nhiêu? Nó được xây dựng cho một startup hay một công ty lớn với lượng người dùng khổng lồ? Người phỏng vấn : Hệ thống phải có khả năng xử lý một lượng lớn yêu cầu.
Ứng viên : Hệ thống có hoạt động trong môi trường phân tán không? Người phỏng vấn : Có.
Ứng viên : Rate limiter là một dịch vụ riêng biệt hay nên được triển khai trong mã ứng dụng? Người phỏng vấn : Đó là một quyết định thiết kế tùy thuộc vào bạn.
Ứng viên : Chúng ta có cần thông báo cho người dùng bị điều tiết không? Người phỏng vấn : Có.
Các yêu cầu Dưới đây là tóm tắt các yêu cầu đối với hệ thống:
-
Giới hạn chính xác các yêu cầu vượt mức.
-
Độ trễ thấp (Low latency). Rate limiter không được làm chậm thời gian phản hồi HTTP.
-
Sử dụng ít bộ nhớ nhất có thể.
-
Giới hạn tốc độ phân tán (Distributed rate limiting). Rate limiter có thể được chia sẻ trên nhiều máy chủ hoặc tiến trình.
-
Xử lý ngoại lệ (Exception handling). Hiển thị các ngoại lệ rõ ràng cho người dùng khi yêu cầu của họ bị điều tiết.
-
Khả năng chịu lỗi cao (High fault tolerance). Nếu có bất kỳ vấn đề nào với rate limiter (ví dụ, một máy chủ cache bị ngoại tuyến), nó sẽ không ảnh hưởng đến toàn bộ hệ thống.
Bước 2 - Đề xuất thiết kế cấp cao và nhận được sự đồng thuận
Chúng ta hãy giữ mọi thứ đơn giản và sử dụng mô hình client-server cơ bản cho việc
Các thuật toán giới hạn tốc độ
Giới hạn tốc độ (rate limiting) có thể được triển khai bằng nhiều thuật toán khác nhau, mỗi thuật toán đều có những ưu và nhược điểm riêng biệt. Mặc dù chương này không tập trung vào các thuật toán, nhưng việc hiểu chúng ở cấp độ cao sẽ giúp chúng ta chọn được thuật toán phù hợp hoặc kết hợp các thuật toán để đáp ứng các trường hợp sử dụng của mình. Dưới đây là danh sách các thuật toán phổ biến:
-
Token bucket
-
Leaking bucket
-
Fixed window counter
-
Sliding window log
-
Sliding window counter
Thuật toán Token bucket Thuật toán Token bucket được sử dụng rộng rãi để giới hạn tốc độ. Nó đơn giản, dễ hiểu và được các công ty internet sử dụng phổ biến. Cả Amazon [5] và Stripe [6] đều sử dụng thuật toán này để điều tiết các API requests của họ.
Thuật toán Token bucket hoạt động như sau:
-
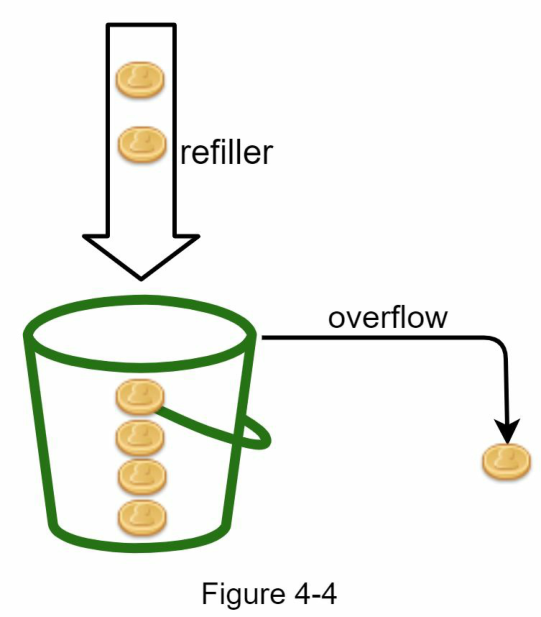
Một token bucket là một thùng chứa có dung lượng được định nghĩa trước. Các token được đưa vào bucket theo tốc độ định sẵn một cách định kỳ. Khi bucket đầy, sẽ không có thêm token nào được thêm vào nữa. Như minh họa trong Hình 4-4, dung lượng của token bucket là 4. Bộ nạp đưa 2 token vào bucket mỗi giây. Khi bucket đầy, các token thừa sẽ bị tràn.
-
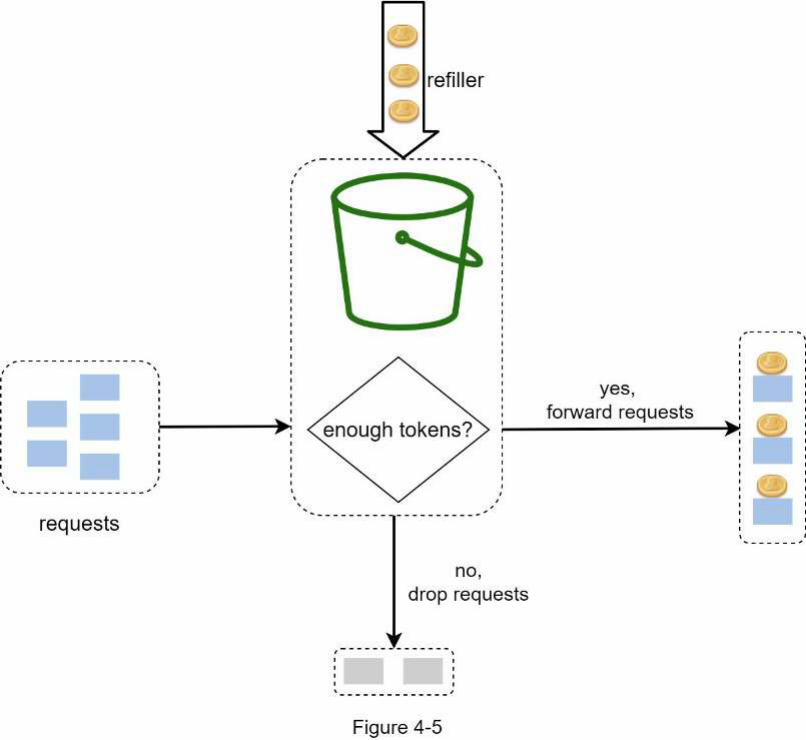
Mỗi request tiêu thụ một token. Khi một request đến, chúng ta kiểm tra xem có đủ token trong bucket hay không. Hình 4-5 giải thích cách nó hoạt động.
-
Nếu có đủ token, chúng ta lấy một token ra cho mỗi request, và request đó được thông qua.
-
Nếu không có đủ token, request sẽ bị loại bỏ.
-
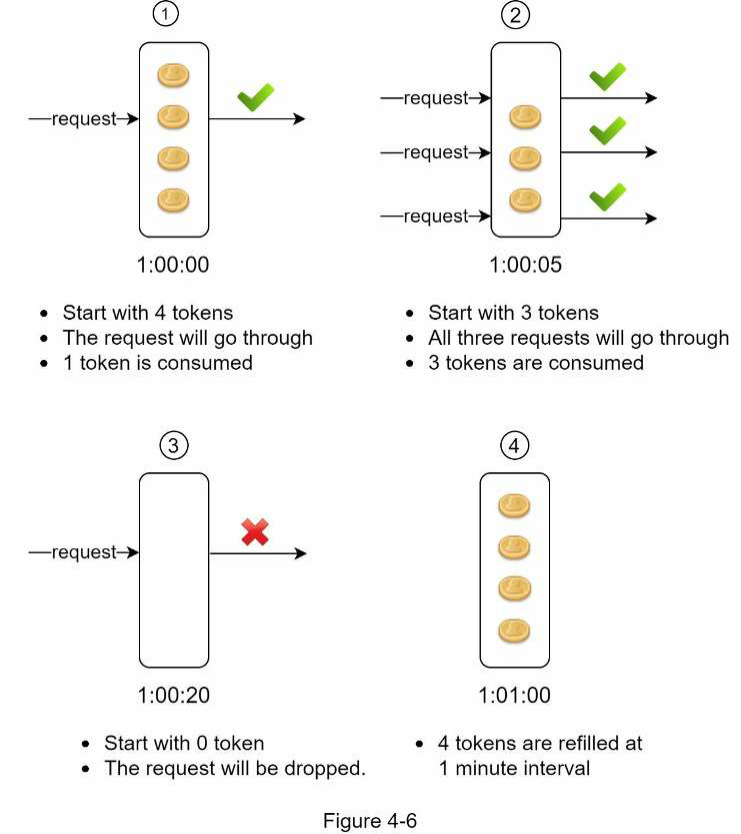
Hình 4-6 minh họa cách hoạt động của việc tiêu thụ token, nạp lại và logic giới hạn tốc độ. Trong ví dụ này, kích thước token bucket là 4, và tốc độ nạp lại là 4 token mỗi 1 phút.
Thuật toán Token bucket có hai tham số:
-
Kích thước bucket: số lượng token tối đa được phép có trong bucket
-
Tốc độ nạp lại: số lượng token đư��ợc đưa vào bucket mỗi giây Chúng ta cần bao nhiêu bucket? Điều này thay đổi và phụ thuộc vào các quy tắc giới hạn tốc độ. Dưới đây là một vài ví dụ.
-
Thông thường, cần có các bucket khác nhau cho các API endpoints khác nhau. Ví dụ, nếu một người dùng được phép tạo 1 bài đăng mỗi giây, thêm 150 bạn bè mỗi ngày và thích 5 bài đăng mỗi giây, thì cần 3 bucket cho mỗi người dùng.
-
Nếu chúng ta cần điều tiết các request dựa trên địa chỉ IP, mỗi địa chỉ IP sẽ yêu cầu một bucket.
-
Nếu hệ thống cho phép tối đa 10.000 request mỗi giây, việc có một bucket toàn cục được chia sẻ bởi tất cả các request là hợp lý. Ưu điểm:
-
Thuật toán dễ triển khai.
-
Hiệu quả về bộ nhớ.
-
Token bucket cho phép xử lý một lưu lượng truy cập đột biến trong thời gian ngắn. Một request có thể được thông qua miễn là còn token. Nhược điểm:
-
Hai tham số trong thuật toán là kích thước bucket và tốc độ nạp lại token. Tuy nhiên, việc điều chỉnh chúng một cách phù hợp có thể là một thách thức.
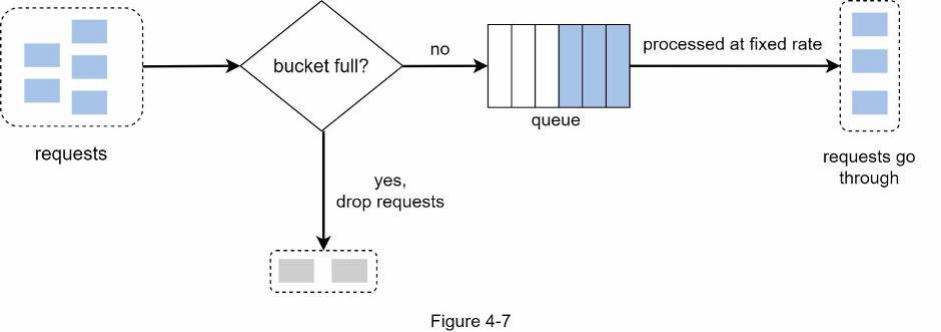
Thuật toán Leaking bucket Thuật toán Leaking bucket tương tự như Token bucket ngoại trừ việc các request được xử lý ở một tốc độ cố định. Nó thường được triển khai bằng một hàng đợi theo nguyên tắc vào trước ra trước (FIFO). Thuật toán hoạt động như sau:
-
Khi một request đến, hệ thống kiểm tra xem hàng đợi có đầy không. Nếu chưa đầy, request sẽ được thêm vào hàng đợi.
-
Ngược lại, request sẽ bị loại b��ỏ.
-
Các request được lấy ra từ hàng đợi và xử lý theo các khoảng thời gian đều đặn.
Hình 4-7 giải thích cách thuật toán hoạt động.
Thuật toán Leaking bucket có hai tham số sau:
-
Kích thước bucket: bằng với kích thước hàng đợi. Hàng đợi chứa các request sẽ được xử lý ở một tốc độ cố định.
-
Tốc độ thoát (Outflow rate): định nghĩa số lượng request có thể được xử lý ở một tốc độ cố định, thường tính bằng giây. Shopify, một công ty thương mại điện tử, sử dụng leaking buckets để giới hạn tốc độ [7].
Ưu điểm:
-
Hiệu quả về bộ nhớ nhờ kích thước hàng đợi giới hạn.
-
Các request được xử lý ở một tốc độ cố định, do đó nó phù hợp cho các trường hợp sử dụng cần tốc độ thoát ổn định.
Nhược điểm:
-
Một lưu lượng truy cập đột biến sẽ làm đầy hàng đợi bằng các request cũ, và nếu chúng không được xử lý kịp thời, các request gần đây sẽ bị giới hạn tốc độ.
-
Có hai tham số trong thuật toán. Việc điều chỉnh chúng một cách phù hợp có thể không dễ dàng.
Thuật toán Fixed window counter Thuật toán Fixed window counter hoạt động như sau:
-
Thuật toán chia dòng thời gian thành các cửa sổ thời gian có kích thước cố định và gán một bộ đếm cho mỗi cửa sổ.
-
Mỗi request sẽ tăng bộ đếm lên một.
-
Khi bộ đếm đạt đến ngưỡng được định nghĩa trước, các request mới sẽ bị loại bỏ cho đến khi một cửa sổ thời gian mới bắt đầu.
 Hãy sử dụng một ví dụ cụ thể để xem cách nó hoạt động. Trong Hình 4-8, đơn vị thời gian là 1 giây và hệ thống cho phép tối đa 3 request mỗi giây. Trong mỗi cửa sổ 1 giây, nếu nhận được hơn 3 request, các request thừa sẽ bị loại bỏ như trong Hình 4-8.
Hãy sử dụng một ví dụ cụ thể để xem cách nó hoạt động. Trong Hình 4-8, đơn vị thời gian là 1 giây và hệ thống cho phép tối đa 3 request mỗi giây. Trong mỗi cửa sổ 1 giây, nếu nhận được hơn 3 request, các request thừa sẽ bị loại bỏ như trong Hình 4-8.
Một vấn đề lớn với thuật toán này là lưu lượng truy cập đột biến tại các cạnh của cửa sổ thời gian có thể khiến số lượng request vượt quá hạn mức cho phép được thông qua. Hãy xem xét trường hợp sau:
Trong Hình 4-9, hệ thống cho phép tối đa 5 request mỗi phút, và hạn mức khả dụng được đặt lại vào phút tròn dễ đọc. Như đã thấy, có năm request trong khoảng từ 2:00:00 đến 2:01:00 và năm request nữa trong khoảng từ 2:01:00 đến 2:02:00. Đối với cửa sổ một phút trong khoảng từ 2:00:30 đến 2:
Thuật toán bộ đếm cửa sổ trượt (Sliding window counter algorithm) Thuật toán bộ đếm cửa sổ trượt là một phương pháp lai (hybrid approach) kết hợp bộ đếm cửa sổ cố định (fixed window counter) và nhật ký cửa sổ trượt (sliding window log). Thuật toán có thể được triển khai bằng hai cách tiếp cận khác nhau. Chúng ta sẽ giải thích một cách triển khai trong phần này và cung cấp tài liệu tham khảo cho cách triển khai còn lại ở cuối phần. Hình 4-11 minh họa cách thuật toán này hoạt động.
Giả sử bộ điều tiết tốc độ (rate limiter) cho phép tối đa 7 yêu cầu mỗi phút, và có 5 yêu cầu trong phút trước và 3 yêu cầu trong phút hiện tại. Đối với một yêu cầu mới đến ở vị trí 30% trong phút hiện tại, số lượng yêu cầu trong cửa sổ trượt (rolling window) được tính bằng công thức sau:
- Số yêu cầu trong cửa sổ hiện tại + số yêu cầu trong cửa sổ trước ***** phần trăm chồng lấn giữa cửa sổ trượt và cửa sổ trước
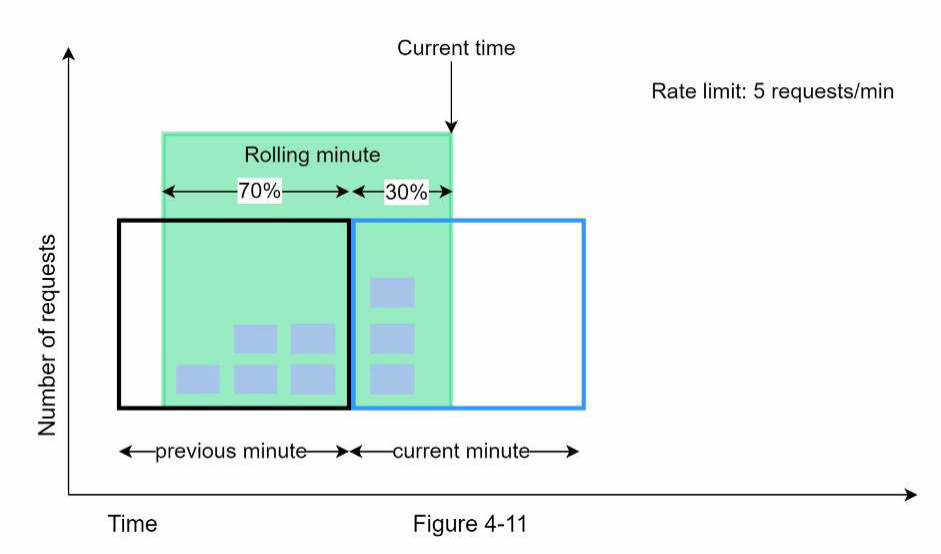
- Sử dụng công thức này, chúng ta có 3 + 5 * 0.7% = 6.5 yêu cầu. Tùy thuộc vào trường hợp sử dụng, con số này có thể được làm tròn lên hoặc xuống. Trong ví dụ của chúng ta, nó được làm tròn xuống thành 6.
Vì bộ điều tiết tốc độ cho phép tối đa 7 yêu cầu mỗi phút, yêu cầu hiện tại có thể được chấp nhận. Tuy nhiên, giới hạn sẽ đạt được sau khi nhận thêm một yêu cầu nữa.
Do giới hạn về không gian, chúng ta sẽ không thảo luận về cách triển khai còn lại ở đây. Độc giả quan tâm nên tham khảo tài liệu [9]. Thuật toán này không hoàn hảo. Nó có những ưu và nhược điểm.
Ưu điểm
-
Nó làm mượt các đợt tăng đột biến trong lưu lượng truy cập vì tốc độ dựa trên tốc độ trung bình của cửa sổ trước.
-
Hiệu quả về bộ nhớ.
Nhược điểm
- Nó chỉ hoạt động hiệu quả với các cửa sổ nhìn lại (look back window) không quá nghiêm ngặt. Đây là một ước tính gần đúng của tốc độ thực tế vì nó giả định các yêu cầu trong cửa sổ trước được phân phối đều. Tuy nhiên, vấn đề này có thể không tệ như vẻ ngoài của nó. Theo các thử nghiệm của Cloudflare [10], chỉ 0.003% yêu cầu bị cho phép hoặc điều tiết tốc độ sai trong số 400 triệu yêu cầu.
Kiến trúc cấp cao (High-level architecture)
Ý tưởng cơ bản của các thuật toán điều tiết tốc độ rất đơn giản. Ở cấp độ cao, chúng ta cần một bộ đếm để theo dõi số lượng yêu cầu được gửi từ cùng một người dùng, địa chỉ IP, v.v. Nếu bộ đếm lớn hơn giới hạn, yêu cầu sẽ bị từ chối.
Chúng ta nên lưu trữ các bộ đếm ở đâu? Sử dụng cơ sở dữ liệu không phải là một ý hay do tốc độ truy cập đĩa chậm. Bộ nhớ đệm trong bộ nhớ (in-memory cache) được chọn vì nó nhanh và hỗ trợ chiến lược hết hạn dựa trên thời gian. Ví dụ, Redis [11] là một lựa chọn phổ biến để triển khai điều tiết tốc độ. Đây là một kho lưu trữ trong bộ nhớ cung cấp hai lệnh: INCR và EXPIRE.
-
INCR: Tăng bộ đếm đã lưu trữ lên 1.
-
EXPIRE: Đặt thời gian chờ cho bộ đếm. Nếu thời gian chờ hết hạn, bộ đếm sẽ tự động bị xóa.
Hình 4-12 cho thấy kiến trúc cấp cao để điều tiết tốc độ, và nó hoạt động như sau:
-
Client gửi yêu cầu đến middleware điều tiết tốc độ.
-
Middleware điều tiết tốc độ lấy bộ đếm từ bucket tương ứng trong Redis và
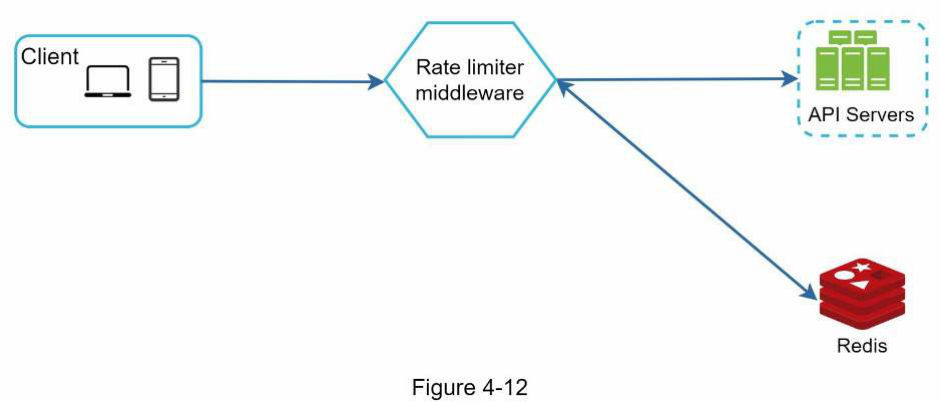 kiểm tra xem giới hạn đã đạt được hay chưa.
kiểm tra xem giới hạn đã đạt được hay chưa.
-
Nếu giới hạn đã đạt, yêu cầu sẽ bị từ chối.
-
Nếu giới hạn chưa đạt, yêu cầu sẽ được gửi đến các API server. Trong khi đó, hệ thống tăng bộ đếm và lưu lại vào Redis.
Bước 3 - Đi sâu vào thiết kế (Design deep dive)
Thiết kế cấp cao trong Hình 4-12 không trả lời các câu hỏi sau:
-
Các quy tắc điều tiết tốc độ được tạo ra như thế nào? Các quy tắc được lưu trữ ở đâu?
-
Làm thế nào để xử lý các yêu cầu bị điều tiết tốc độ?
Trong phần này, chúng ta sẽ trả lời các câu hỏi liên quan đến quy tắc điều tiết tốc độ và sau đó xem xét các chiến lược để xử lý các yêu cầu bị điều tiết tốc độ. Cuối cùng, chúng ta sẽ thảo luận về điều tiết tốc độ trong môi trường phân tán, một thiết kế chi tiết, tối ưu hóa hiệu suất và giám sát.
Các quy tắc điều tiết tốc độ (Rate limiting rules)
Lyft đã mã nguồn mở thành phần điều tiết tốc độ của họ [12]. Chúng ta sẽ xem xét bên trong thành phần này và xem một số ví dụ về các quy tắc điều tiết tốc độ:
domain: messaging descriptors:
- key: message_type Value: marketing rate_limit: unit: day requests_per_unit: 5
Trong ví dụ trên, hệ thống được cấu hình để cho phép tối đa 5 tin nhắn tiếp thị mỗi ngày. Đây là một ví dụ khác:
domain: auth descriptors:
- key: auth_type Value: login rate_limit: unit: minute requests_per_unit: 5
Quy tắc này cho thấy client không được phép đăng nhập quá 5 lần trong 1 phút. Các quy tắc thường được viết trong các tệp cấu hình và lưu trên đĩa.
Vượt quá giới hạn điều tiết tốc độ (Exceeding the rate limit)
Trong trường hợp một yêu cầu bị điều tiết tốc độ, các API trả về mã phản hồi HTTP 429 (too many requests) cho client. Tùy thuộc vào các trường hợp sử dụng, chúng ta có thể đưa các yêu cầu bị điều tiết tốc độ vào hàng đợi để xử lý sau. Ví dụ, nếu một số đơn hàng bị điều tiết tốc độ do hệ thống quá tải, chúng ta có thể giữ lại các đơn hàng đó để xử lý sau.
Header của bộ điều tiết tốc độ (Rate limiter headers) Làm thế nào để client biết liệu nó có đang bị điều tiết tốc độ hay không? Và làm thế nào để client biết số lượng yêu cầu còn lại được phép trước khi bị điều tiết tốc độ? Câu trả lời nằm ở các HTTP response header. Bộ điều tiết tốc độ trả về các HTTP header sau cho client:
X-Ratelimit-Remaining : Số lượng yêu cầu còn lại được phép trong cửa sổ.
X-Ratelimit-Limit: Nó cho biết client có thể thực hiện bao nhiêu cuộc gọi mỗi cửa sổ thời gian.
X-Ratelimit-Retry-After: Số giây phải đợi cho đến khi bạn có thể thực hiện lại yêu cầu mà không bị điều tiết tốc độ.
Khi người dùng đã gửi quá nhiều yêu cầu, lỗi 429 too many requests và header X-Ratelimit-Retry-After sẽ được trả về cho client.
Thiết kế chi tiết (Detailed design)
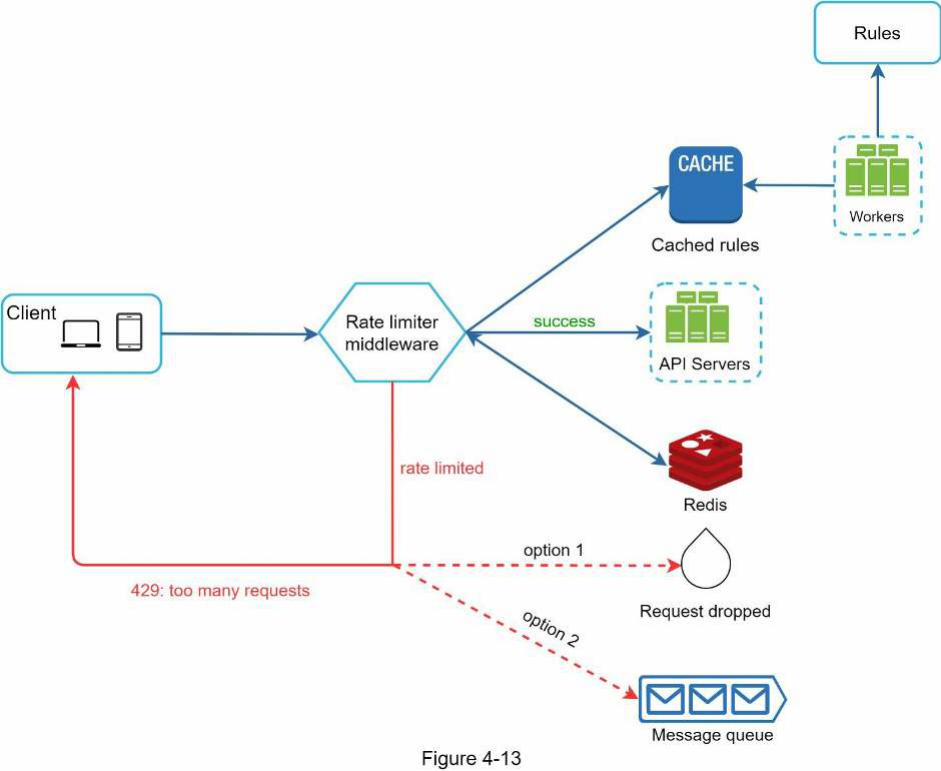
Hình 4-13 trình bày một thiết kế chi tiết của hệ thống.
-
Các quy tắc được lưu trữ trên đĩa. Các worker thường xuyên lấy các quy tắc từ đĩa và lưu trữ chúng trong bộ nhớ đệm (cache).
-
Khi client gửi yêu cầu đến server, yêu cầu sẽ được gửi đến middleware điều tiết tốc độ trước tiên.
-
Middleware điều tiết tốc độ tải các quy tắc từ bộ nhớ đệm. Nó lấy các bộ đếm và dấu thời gian của yêu cầu cuối cùng từ Redis cache. Dựa trên phản hồi, bộ điều tiết tốc độ quyết định:
-
nếu yêu cầu không bị điều tiết tốc độ, nó sẽ được chuyển tiếp đến các API server.
-
nếu yêu cầu bị điều tiết tốc độ, bộ điều tiết tốc độ sẽ trả về lỗi 429 too many requests cho client. Trong khi đó, yêu cầu sẽ bị loại bỏ hoặc chuyển tiếp đến hàng đợi.
-
Rate limiter trong môi trường phân tán
Xây dựng một rate limiter hoạt động trong môi trường máy chủ đơn lẻ không khó. Tuy nhiên, mở rộng hệ thống để hỗ trợ nhiều máy chủ và các luồng đồng thời (tiếng Anh: concurrent threads) lại là một vấn đề khác. Có hai thách thức:
- Race condition
- Vấn đề đồng bộ hóa (tiếng Anh: synchronization issue)
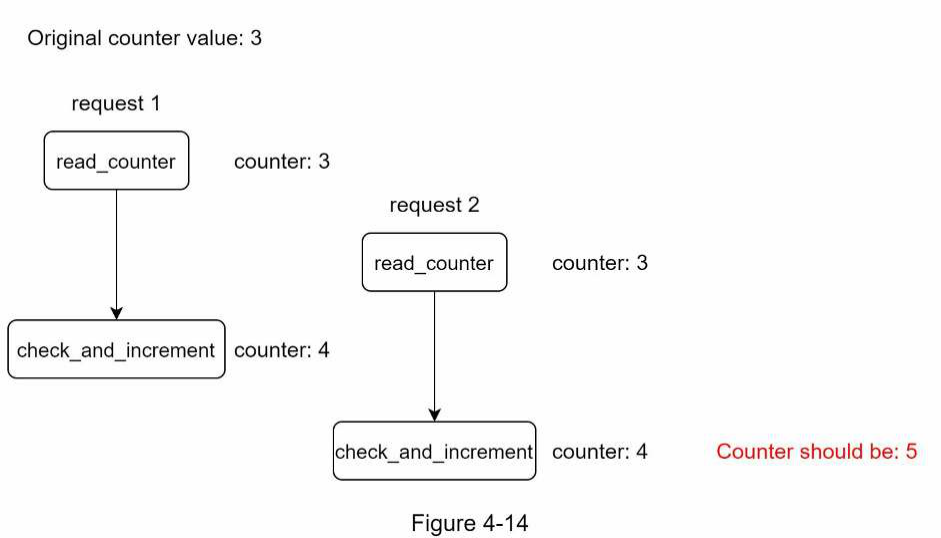
Race condition Như đã thảo luận trước đó, rate limiter hoạt động ở cấp độ cao như sau:
- Đọc giá trị counter từ Redis.
- Kiểm tra xem ( counter + 1 ) có vượt quá ngưỡng hay không.
- Nếu không, tăng giá trị counter lên 1 trong Redis.
Race condition có thể xảy ra trong môi trường có tính đồng thời cao (tiếng Anh: highly concurrent environment) như minh họa trong Hình 4-14.
Giả sử giá trị counter trong Redis là 3. Nếu hai yêu cầu cùng lúc đọc giá trị counter trước khi một trong số chúng ghi giá trị trở lại, mỗi yêu cầu sẽ tăng counter lên một và ghi lại mà không kiểm tra luồng (thread) còn lại. Cả hai yêu cầu (luồng) đều tin rằng chúng có giá trị counter đúng là 4. Tuy nhiên, giá trị counter đúng phải là 5.
Khóa (tiếng Anh: locks) là giải pháp rõ ràng nhất để giải quyết race condition. Tuy nhiên, khóa sẽ làm chậm hệ thống đáng kể. Hai chiến lược thường được sử dụng để giải quyết vấn đề này là: script Lua (tiếng Anh: Lua script) [13] và cấu trúc dữ liệu sorted sets (tiếng Anh: sorted sets) trong Redis [8]. Đối với những độc giả quan tâm đến các chiến lược này, hãy tham khảo các tài liệu tham khảo tương ứng [8] [13].
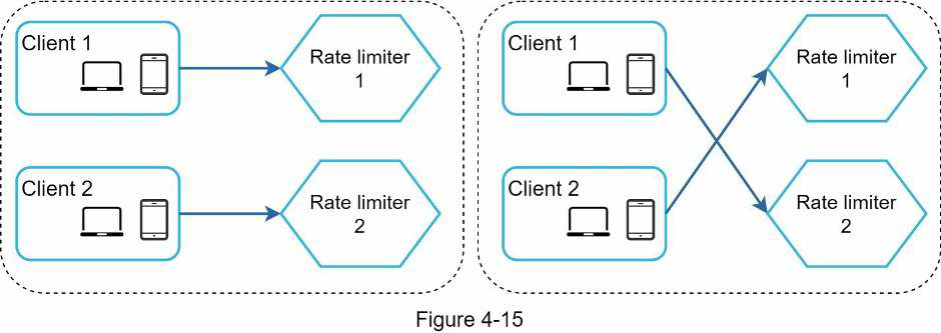
Vấn đề đồng bộ hóa Đồng bộ hóa (tiếng Anh: synchronization) là một yếu tố quan trọng khác cần xem xét trong môi trường phân tán. Để hỗ trợ hàng triệu người dùng, một máy chủ rate limiter có thể không đủ để xử lý lưu lượng truy cập. Khi sử dụng nhiều máy chủ rate limiter, việc đồng bộ hóa là cần thiết. Ví dụ, ở phía bên trái của Hình 4-15, client 1 gửi yêu cầu đến rate limiter 1, và client 2 gửi yêu cầu đến
 rate limiter 2. Vì tầng web (tiếng Anh: web tier) là stateless (không trạng thái), các client có thể gửi yêu cầu đến một rate limiter khác như minh họa ở phía bên phải của Hình 4-15. Nếu không có đồng bộ hóa, rate limiter 1 sẽ không chứa bất kỳ dữ liệu nào về client 2. Do đó, rate limiter không thể hoạt động đúng cách.
rate limiter 2. Vì tầng web (tiếng Anh: web tier) là stateless (không trạng thái), các client có thể gửi yêu cầu đến một rate limiter khác như minh họa ở phía bên phải của Hình 4-15. Nếu không có đồng bộ hóa, rate limiter 1 sẽ không chứa bất kỳ dữ liệu nào về client 2. Do đó, rate limiter không thể hoạt động đúng cách.
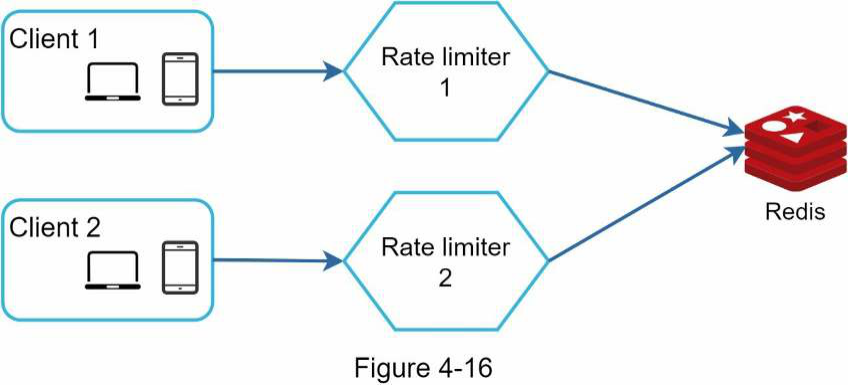
Một giải pháp khả thi là sử dụng sticky sessions (phiên cố định) cho phép client gửi lưu lượng truy cập đến cùng một rate limiter. Giải pháp này không được khuyến khích vì nó không có khả năng mở rộng (tiếng Anh: scalable) cũng như không linh hoạt (tiếng Anh: flexible). Một cách tiếp cận tốt hơn là sử dụng các kho dữ liệu tập trung (tiếng Anh: centralized data stores) như Redis. Thiết kế được thể hiện trong Hình 4-16.
Tối ưu hóa hiệu suất
Tối ưu hóa hiệu suất (tiếng Anh: performance optimization) là một chủ đề phổ biến trong các buổi phỏng vấn thiết kế hệ thống. Chúng ta sẽ đề cập đến hai lĩnh vực cần cải thiện.
Thứ nhất, thiết lập đa trung tâm dữ liệu (tiếng Anh: multi-data center setup) là rất quan trọng đối với một rate limiter vì độ trễ (tiếng Anh: latency) cao đối với người dùng ở xa trung tâm dữ liệu. Hầu hết các nhà cung cấp dịch vụ đám mây (tiếng Anh: cloud service providers) xây dựng nhiều vị trí máy chủ biên (tiếng Anh: edge server locations) trên khắp thế giới. Ví dụ, tính đến ngày 20/05/2020, Cloudflare có 194 máy chủ biên phân tán về mặt địa lý [14]. Lưu lượng truy cập được tự động định tuyến đến máy chủ biên gần nhất để giảm độ trễ.
Thứ hai, đồng bộ hóa dữ liệu bằng mô hình nhất quán cuối cùng (tiếng Anh: eventual consistency model). Nếu bạn chưa rõ về mô hình nhất quán cuối cùng, hãy tham khảo phần “Consistency” trong “Chương 6: Thiết kế một Kho khóa-giá trị (tiếng Anh: Key-value Store).”
Giám sát
Sau khi rate limiter được triển khai, việc thu thập dữ liệu phân tích (tiếng Anh: analytics data) để kiểm tra xem rate limiter có hiệu quả hay không là rất quan trọng. Chủ yếu, chúng ta muốn đảm bảo rằng:
- Thuật toán giới hạn tốc độ (tiếng Anh: rate limiting algorithm) hiệu quả.
- Các quy tắc giới hạn tốc độ (tiếng Anh: rate limiting rules) hiệu quả.
Ví dụ, nếu các quy tắc giới hạn tốc độ quá nghiêm ngặt, nhiều yêu cầu hợp lệ sẽ bị loại bỏ. Trong trường hợp này, chúng ta muốn nới lỏng các quy tắc một chút. Trong một ví dụ khác, chúng ta nhận thấy rate limiter của mình trở nên kém hiệu quả khi có sự gia tăng đột ngột về lưu lượng truy cập, chẳng hạn như trong các đợt flash sale. Trong kịch bản này, chúng ta có thể thay thế thuật toán để hỗ trợ lưu lượng truy cập đột biến (tiếng Anh: burst traffic). Token bucket là một lựa chọn phù hợp ở đây.
Bước 4 - Tổng kết
Trong chương này, chúng ta đã thảo luận về các thuật toán giới hạn tốc độ khác nhau cùng với ưu/nhược điểm của chúng. Các thuật toán đã thảo luận bao gồm:
- Token bucket
- Leaking bucket
- Fixed window
- Sliding window log
- Sliding window counter
Sau đó, chúng ta đã thảo luận về kiến trúc hệ thống, rate limiter trong môi trường phân tán, tối ưu hóa hiệu suất và giám sát. Tương tự như bất kỳ câu hỏi phỏng vấn thiết kế hệ thống nào, có những điểm bổ sung bạn có thể đề cập nếu thời gian cho phép:
- Giới hạn tốc độ cứng (Hard) so với mềm (Soft).
- Cứng: Số lượng yêu cầu không thể vượt quá ngưỡng.
- Mềm: Yêu cầu có thể vượt quá ngưỡng trong một khoảng thời gian ngắn.
- Giới hạn tốc độ ở các cấp độ khác nhau. Trong chương này, chúng ta chỉ nói về giới hạn tốc độ ở cấp độ ứng dụng (tiếng Anh: application level) (HTTP: lớp 7). Có thể áp dụng giới hạn tốc độ ở các lớp khác. Ví dụ, bạn có thể áp dụng giới hạn tốc độ theo địa chỉ IP bằng cách sử dụng Iptables [15] (IP: lớp 3). Lưu ý: Mô hình Kết nối Hệ thống Mở (OSI model) có 7 lớp [16]: Lớp 1: Lớp vật lý (tiếng Anh: Physical layer), Lớp 2: Lớp liên kết dữ liệu (tiếng Anh: Data link layer), Lớp 3: Lớp mạng (tiếng Anh: Network layer), Lớp 4: Lớp vận chuyển (tiếng Anh: Transport layer), Lớp 5: Lớp phiên (tiếng Anh: Session layer), Lớp 6: Lớp trình bày (tiếng Anh: Presentation layer), Lớp 7: Lớp ứng dụng (tiếng Anh: Application layer).
- Tránh bị giới hạn tốc độ. Thiết kế client của bạn với các phương pháp hay nhất (tiếng Anh: best practices):
- Sử dụng bộ nhớ đệm (cache) phía client (tiếng Anh: client cache) để tránh thực hiện các lệnh gọi API thường xuyên.
- Hiểu rõ giới hạn và không gửi quá nhiều yêu cầu trong một khoảng thời gian ngắn.
- Bao gồm mã để bắt các ngoại lệ (tiếng Anh: exceptions) hoặc lỗi để client của bạn có thể phục hồi một cách linh hoạt từ các ngoại lệ.
- Thêm đủ thời gian back off (tiếng Anh: back off time) vào logic thử lại (tiếng Anh: retry logic). Chúc mừng bạn đã đi được đến đây! Bây giờ hãy tự thưởng cho mình một lời khen. Làm tốt lắm!
Tài liệu tham khảo
[1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limitingstrategies-techniques
[2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits
[3] Google docs usage limits: https://developers.google.com/docs/api/limits
[4] IBM microservices: https://www.ibm.com/cloud/learn/microservices
[5] Throttle API requests for better throughput: https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-requestthrottling.html
[6] Stripe rate limiters: https://stripe.com/blog/rate-limiters
[7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/restadmin-api-rate-limits
[8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
[9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling9304b0d18250
[10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
[11] Redis website: https://redis.io/
[12] Lyft rate limiting: https://github.com/lyft/ratelimit
[13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
[14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/whatis-edge-computing/
[15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-withiptables
[16] OSI model: https://en.wikipedia.org/wiki/OSI_model#Layer_architecture
Made by Anh Tu - Share to be share