[System design interview] CHƯƠNG 15: THIẾT KẾ GOOGLE DRIVE

Đây là bản dịch tiếng Việt của "System design interview" (Tác giả: Unknown Author). Bài được dịch tự động bởi Aha! Mind Interpreter — pipeline dịch sách kỹ thuật sử dụng Gemini Flash.
⚠️ Bản dịch tự động — có thể có lỗi. Vui lòng đối chiếu với bản gốc tiếng Anh khi cần độ chính xác cao.
CHƯƠNG 15: THIẾT KẾ GOOGLE DRIVE
Trong những năm gần đây, các dịch vụ lưu trữ đám mây như Google Drive, Dropbox, Microsoft OneDrive và Apple iCloud đã trở nên rất phổ biến. Trong chương này, chúng ta sẽ được yêu cầu thiết kế Google Drive.
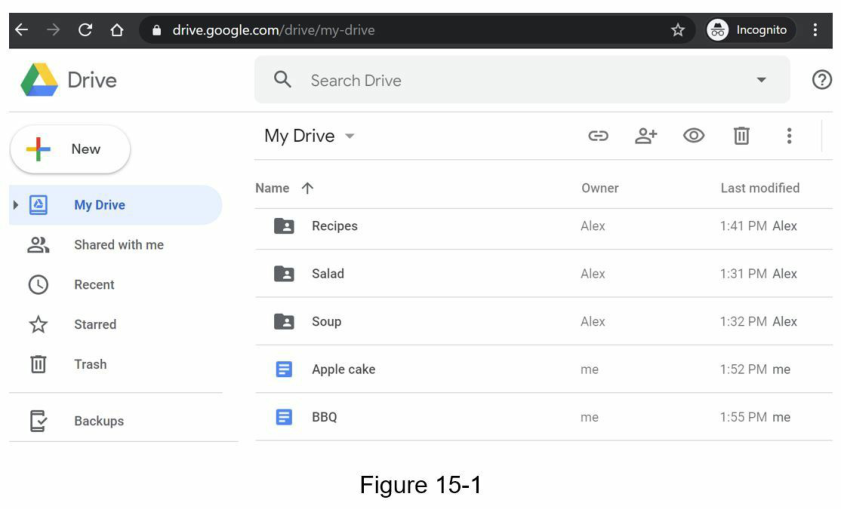
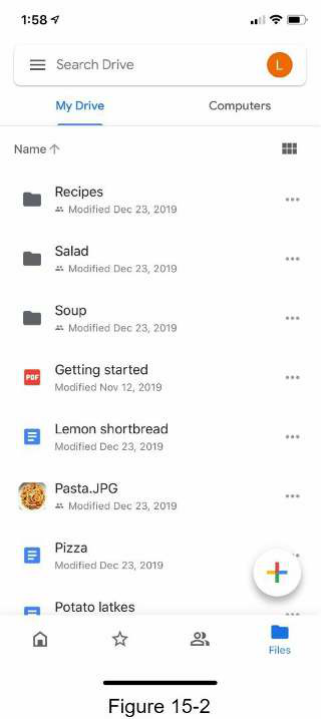
Trước khi đi sâu vào thiết kế, chúng ta hãy dành một chút thời gian để tìm hiểu về Google Drive. Google Drive là một dịch vụ lưu trữ và đồng bộ hóa tệp tin, giúp chúng ta lưu trữ tài liệu, ảnh, video và các tệp tin khác trên đám mây. Chúng ta có thể truy cập các tệp tin của mình từ bất kỳ máy tính, điện thoại thông minh hoặc máy tính bảng nào. Chúng ta cũng có thể dễ dàng chia sẻ các tệp tin đó với bạn bè, gia đình và đồng nghiệp [1]. Hình 15-1 và 15-2 lần lượt cho thấy giao diện của Google Drive trên trình duyệt và ứng dụng di động.
Bước 1 - Hiểu vấn đề và xác định phạm vi thiết kế
Thiết kế Google Drive là một dự án lớn, vì vậy điều quan trọng là phải đặt câu hỏi để thu hẹp phạm vi thiết kế.
Ứng viên : Các tính năng quan trọng nhất là gì? Người phỏng vấn : Tải lên và tải xuống tệp tin, đồng bộ hóa tệp tin (file sync) và thông báo.
Ứng viên : Đây là ứng dụng di động, ứng dụng web hay cả hai? Người phỏng vấn : Cả hai.
Ứng viên : Các định dạng tệp tin được hỗ trợ là gì? Người phỏng vấn : Bất kỳ loại tệp tin nào.
Ứng viên : Các tệp tin có cần được mã hóa không? Người phỏng vấn : Có, các tệp tin trong hệ thống lưu trữ phải được mã hóa.
Ứng viên : Có giới hạn kích thước tệp tin không? Người phỏng vấn : Có, các tệp tin phải có kích thước 10 GB hoặc nhỏ hơn.
Ứng viên : Sản phẩm có bao nhiêu người dùng? Người phỏng vấn : 10 triệu DAU.
Trong chương này, chúng ta sẽ tập trung vào các tính năng sau:
-
Thêm tệp tin. Cách dễ nhất để thêm tệp tin là kéo và thả tệp tin vào Google Drive.
-
Tải xuống tệp tin.
-
Đồng bộ hóa tệp tin trên nhiều thiết bị. Khi một tệp tin được thêm vào một thiết bị, nó sẽ tự động được đồng bộ hóa với các thiết bị khác.
-
Xem các phiên bản tệp tin (file revisions).
-
Chia sẻ tệp tin với bạn bè, gia đình và đồng nghiệp.
-
Gửi thông báo khi một tệp tin được chỉnh sửa, xóa hoặc được chia sẻ với bạn.
Các tính năng không được thảo luận trong chương này bao gồm:
- Chỉnh sửa và cộng tác trên Google Doc. Google Doc cho phép nhiều người cùng chỉnh sửa một tài liệu đồng thời. Tính năng này nằm ngoài phạm vi thiết kế của chúng ta.
Ngoài việc làm rõ các yêu cầu, điều quan trọng là phải hiểu các yêu cầu phi chức năng (non-functional requirements):
-
Độ tin cậy (Reliability). Độ tin cậy cực kỳ quan trọng đối với một hệ thống lưu trữ. Mất dữ liệu là điều không thể chấp nhận được.
-
Tốc độ đồng bộ hóa nhanh. Nếu việc đồng bộ hóa tệp tin mất quá nhiều thời gian, người dùng sẽ mất kiên nhẫn và từ bỏ sản phẩm.
-
Mức sử dụng băng thông (Bandwidth usage). Nếu một sản phẩm tiêu tốn nhiều băng thông mạng không cần thiết, người dùng sẽ không hài lòng, đặc biệt khi họ đang sử dụng gói dữ liệu di động.
-
Khả năng mở rộng (Scalability). Hệ thống phải có khả năng xử lý lượng truy cập lớn.
-
Tính sẵn sàng cao (High availability). Người dùng vẫn có thể sử dụng hệ thống ngay cả khi một số máy chủ ngoại tuyến, bị chậm hoặc gặp lỗi mạng không mong muốn.
Ước tính sơ bộ
-
Giả sử ứng dụng có 50 triệu người dùng đã đăng ký và 10 triệu DAU.
-
Người dùng nhận được 10 GB dung lượng miễn phí.
-
Giả sử người dùng tải lên 2 tệp tin mỗi ngày. Kích thước tệp tin trung bình là 500 KB.
-
Tỷ lệ đọc/ghi là 1:1.
-
Tổng dung lượng được cấp phát: 50 triệu * 10 GB = 500 Petabyte
-
QPS (Queries Per Second) cho API tải lên: 10 triệu * 2 lượt tải lên / 24 giờ / 3600 giây = ~ 240
-
QPS cao điểm = QPS * 2 = 480
Bước 2 - Đề xuất thiết kế cấp cao và nhận được sự đồng thuận
Thay vì trình bày sơ đồ thiết kế cấp cao (high-level design) ngay từ đầu, chúng ta sẽ sử dụng một cách tiếp cận hơi khác. Chúng ta sẽ bắt đầu với một thứ đơn giản: xây dựng mọi thứ trên một máy chủ duy nhất. Sau đó, dần dần mở rộng quy mô để hỗ trợ hàng triệu người dùng. Bằng cách thực hiện bài tập này, nó sẽ giúp chúng ta ôn lại một số chủ đề quan trọng đã được đề cập trong sách.
Chúng ta hãy bắt đầu với thiết lập máy chủ đơn lẻ như liệt kê dưới đây:
-
Một máy chủ web (web server) để tải lên và tải xuống tệp tin.
-
Một cơ sở dữ liệu (database) để theo dõi siêu dữ liệu (metadata) như dữ liệu người dùng, thông tin đăng nhập, th�ông tin tệp tin, v.v.
-
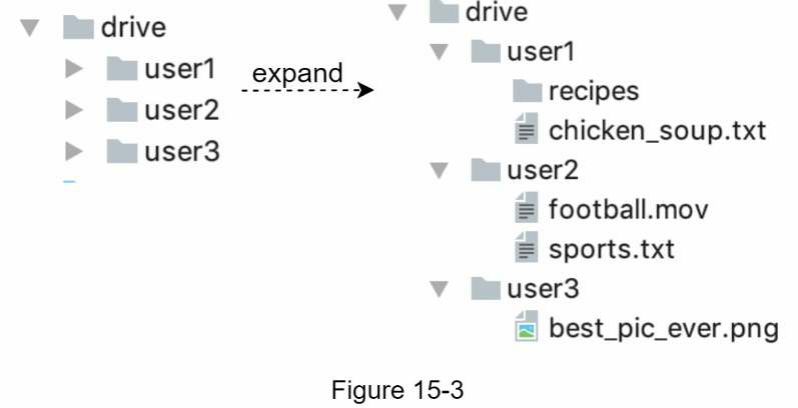
Một hệ thống lưu trữ để lưu trữ tệp tin. Chúng ta cấp phát 1TB dung lượng lưu trữ để chứa các tệp tin. Chúng ta dành vài giờ để thiết lập một máy chủ web Apache, một cơ sở dữ liệu MySQL và một thư mục có tên drive/ làm thư mục gốc để lưu trữ các tệp tin đã tải lên. Bên dưới thư mục drive/, có một danh sách các thư mục, được gọi là không gian tên (namespaces). Mỗi không gian tên chứa tất cả các tệp tin đã tải lên của người dùng đó. Tên tệp tin trên máy chủ được giữ nguyên như tên tệp tin gốc. Mỗi tệp tin hoặc thư mục có thể được nhận diện duy nhất bằng cách kết hợp không gian tên và đường dẫn tương đối (relative path).
Hình 15-3 cho thấy một ví dụ về cách thư mục /drive trông như thế nào ở phía bên trái và chế độ xem mở rộng của nó ở phía bên phải.
API
Các API sẽ trông như thế nào? Chúng ta chủ yếu cần 3 API: tải lên tệp tin, tải xuống tệp tin và lấy các phiên bản tệp tin.
1. Tải tệp tin lên Google Drive Hai loại tải lên được hỗ trợ:
-
Tải lên đơn giản (Simple upload). Sử dụng loại tải lên này khi kích thước tệp tin nhỏ.
-
Tải lên có thể tiếp tục (Resumable upload). Sử dụng loại tải lên này khi kích thước tệp tin lớn và có khả năng cao bị gián đoạn mạng.
Dưới đây là một ví dụ về API tải lên có thể tiếp tục: https://api.example.com/files/upload?uploadType=resumable
Tham số:
-
uploadType=resumable
-
data: Tệp tin cục bộ cần tải lên.
 Việc tải lên có thể tiếp tục được thực hiện thông qua 3 bước sau [2]:
Việc tải lên có thể tiếp tục được thực hiện thông qua 3 bước sau [2]:
-
Gửi yêu cầu ban đầu để lấy URL có thể tiếp tục.
-
Tải dữ liệu lên và theo dõi trạng thái tải lên.
-
Nếu quá trình tải lên bị gián đoạn, hãy tiếp tục tải lên.
2. Tải tệp tin từ Google Drive Ví dụ API: https://api.example.com/files/download
Tham số:
- path: Đường dẫn tệp tin cần tải xuống. Ví dụ tham số:
{
"path": "/recipes/soup/best_soup.txt"
}
3. Lấy các phiên bản tệp tin Ví dụ API: https://api.example.com/files/list_revisions
Tham số:
-
path: Đường dẫn đến tệp tin mà bạn muốn lấy lịch sử phiên bản.
-
limit: Số lượng phiên bản tối đa cần trả về. Ví dụ tham số:
{
"path": "/recipes/soup/best_soup.txt",
"limit": 20
}
Tất cả các API đều yêu cầu xác thực người dùng và sử dụng HTTPS. Secure Sockets Layer (SSL) bảo vệ việc truyền dữ liệu giữa máy khách và máy chủ backend (backend servers).
Thoát khỏi máy chủ đơn lẻ
Khi ngày càng nhiều tệp được tải lên, cuối cùng chúng ta sẽ nhận được cảnh báo đầy dung lượng như thể hiện trong Hình 15-4.
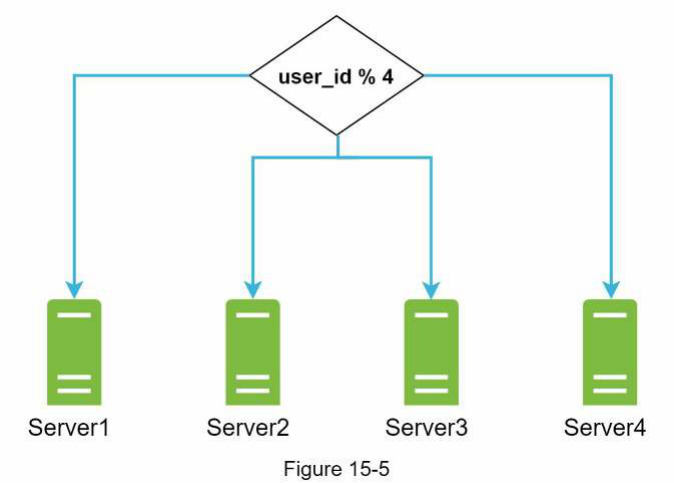
Chỉ còn 10 MB dung lượng lưu trữ! Đây là một trường hợp khẩn cấp vì người dùng không thể tải tệp lên được nữa. Giải pháp đầu tiên nảy ra trong đầu là phân mảnh dữ liệu (sharding), để dữ liệu được lưu trữ trên nhiều máy chủ lưu trữ. Hình 15-5 cho thấy một ví dụ về phân mảnh dựa trên user_id .

Bạn thức trắng đêm để thiết lập sharding cơ sở dữ liệu và theo dõi chặt chẽ. Mọi thứ lại hoạt động trơn tru. Bạn đã dập tắt được "đám cháy", nhưng vẫn lo lắng về khả năng mất dữ liệu trong trường hợp máy chủ lưu trữ gặp sự cố. Bạn hỏi xung quanh và người bạn chuyên gia backend của bạn, Frank, nói rằng nhiều công ty hàng đầu như Netflix và Airbnb sử dụng Amazon S3 để lưu trữ. "Amazon Simple Storage Service (Amazon S3) là một dịch vụ lưu trữ đối tượng (object storage service) cung cấp khả năng mở rộng, tính sẵn sàng dữ liệu, bảo mật và hiệu suất hàng đầu trong ngành" [3]. Bạn quyết định nghiên cứu để xem liệu nó có phù hợp hay không.
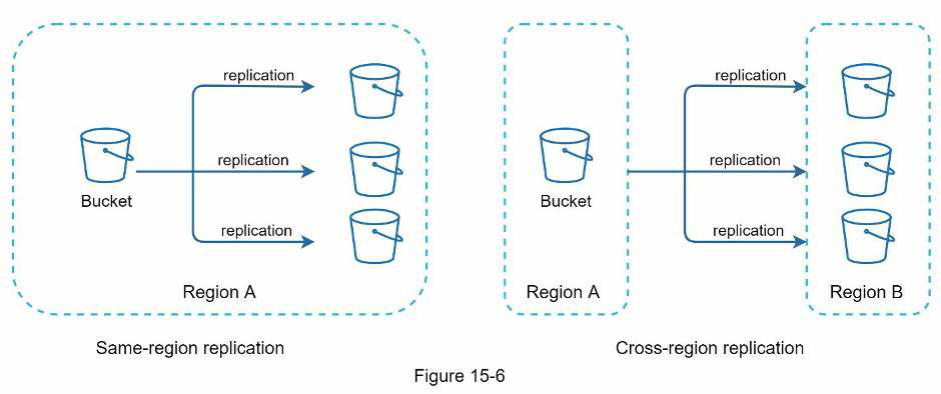
Sau nhiều nghiên cứu, bạn đã hiểu rõ về hệ thống lưu trữ S3 và quyết định lưu trữ tệp trong S3. Amazon S3 hỗ trợ nhân bản trong cùng khu vực (same-region) và nhân bản liên khu vực (cross-region replication). Một khu vực (region) là một khu vực địa lý nơi các dịch vụ web của Amazon (AWS) có các trung tâm dữ liệu (data centers). Như thể hiện trong Hình 15-6, dữ liệu có thể được nhân bản trong cùng khu vực (phía bên trái) và liên khu vực (phía bên phải). Các tệp dự phòng được lưu trữ ở nhiều khu vực để chống mất dữ liệu và đảm bảo tính sẵn sàng. Một bucket giống như một thư mục trong hệ thống tệp.
Sau khi đưa các tệp vào S3, cuối cùng bạn có thể ngủ ngon mà không phải lo lắng về việc mất dữ liệu. Để ngăn chặn các vấn đề tương tự xảy ra trong tương lai, bạn quyết định nghiên cứu thêm về các lĩnh vực có thể cải thiện. Dưới đây là một vài lĩnh vực bạn tìm thấy:
- Load balancer: Thêm một Load balancer để phân phối lưu lượng mạng. Một Load balancer đảm bảo
 lưu lượng được phân phối đồng đều, và nếu một máy chủ web gặp sự cố, nó sẽ phân phối lại lưu lượng.
lưu lượng được phân phối đồng đều, và nếu một máy chủ web gặp sự cố, nó sẽ phân phối lại lưu lượng.
-
Máy chủ web: Sau khi thêm Load balancer, có thể dễ dàng thêm/bớt các máy chủ web, tùy thuộc vào tải lưu lượng.
-
Metadata database: Di chuyển cơ sở dữ liệu ra khỏi máy chủ để tránh điểm lỗi đơn (single point of failure). Đồng thời, thiết lập nhân bản dữ liệu và sharding để đáp ứng các yêu cầu về tính sẵn sàng và khả năng mở rộng.
-
Lưu trữ tệp: Amazon S3 được sử dụng để lưu trữ tệp. Để đảm bảo tính sẵn sàng và độ bền, các tệp được nhân bản ở hai khu vực địa lý riêng biệt.
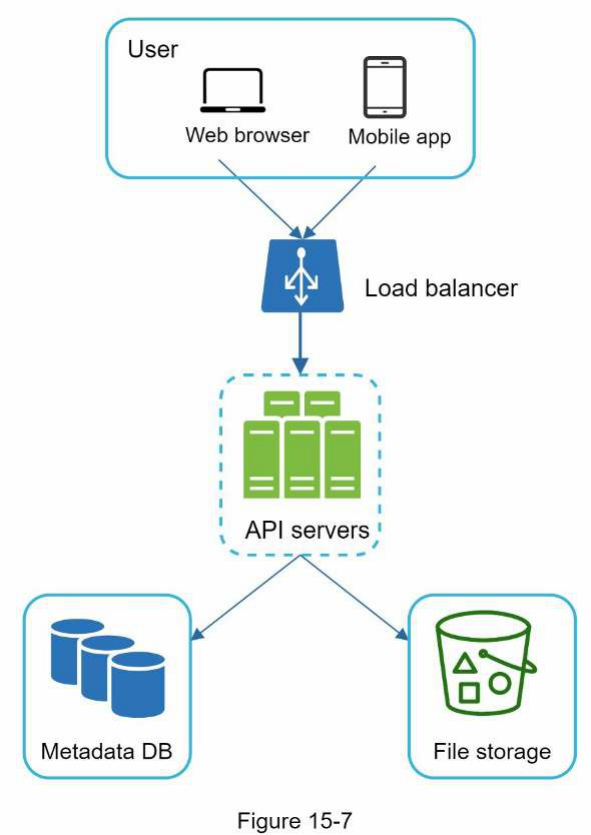
Sau khi áp dụng các cải tiến trên, bạn đã tách rời thành công các máy chủ web, Metadata database và lưu trữ tệp khỏi một máy chủ đơn lẻ. Thiết kế cập nhật được thể hiện trong Hình 15-7.
Xung đột đồng bộ
Đối với một hệ thống lưu trữ lớn như Google Drive, xung đột đồng bộ (sync conflicts) thỉnh thoảng vẫn xảy ra. Khi hai người dùng sửa đổi cùng một tệp hoặc thư mục cùng một lúc, một xung đột sẽ xảy ra. Làm thế nào chúng ta có thể giải quyết xung đột? Đây là chiến lược của chúng ta: phiên bản được xử lý trước sẽ thắng, và phiên bản được xử lý sau sẽ nhận được thông báo xung đột. Hình 15-8 cho thấy một ví dụ về xung đột đồng bộ.
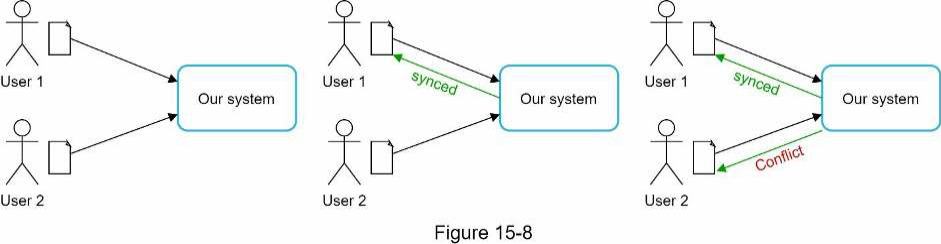
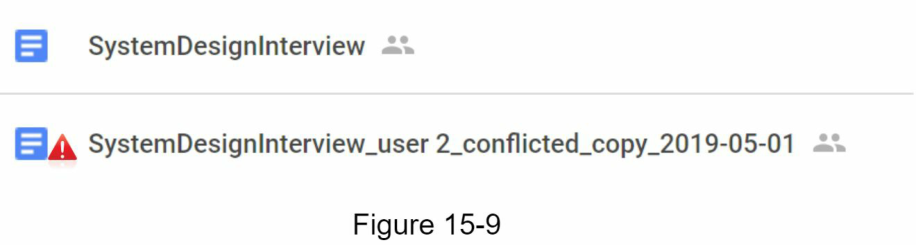
Trong Hình 15-8, người dùng 1 và người dùng 2 cố gắng cập nhật cùng một tệp cùng một lúc, nhưng tệp của người dùng 1 được hệ thống của chúng ta xử lý trước. Thao tác cập nhật của người dùng 1 được thực hiện thành công, nhưng người dùng 2 gặp xung đột đồng bộ. Làm thế nào chúng ta có thể giải quyết xung đột cho người dùng 2? Hệ thống của chúng ta hiển thị cả hai bản sao của cùng một tệp: bản sao cục bộ của người dùng 2 và phiên bản mới nhất từ máy chủ (Hình 15-9). Người dùng 2 có tùy chọn hợp nhất cả hai tệp hoặc ghi đè một phiên bản bằng phiên bản kia.
Khi nhiều người dùng cùng lúc chỉnh sửa cùng một tài liệu, việc giữ tài liệu được đồng bộ hóa là một thách thức. Độc giả quan tâm nên tham khảo tài liệu tham khảo [4] [5].
Thiết kế cấp cao
Hình 15-10 minh họa thiết kế cấp cao được đề xuất. Hãy cùng chúng ta xem xét từng thành phần của hệ thống.
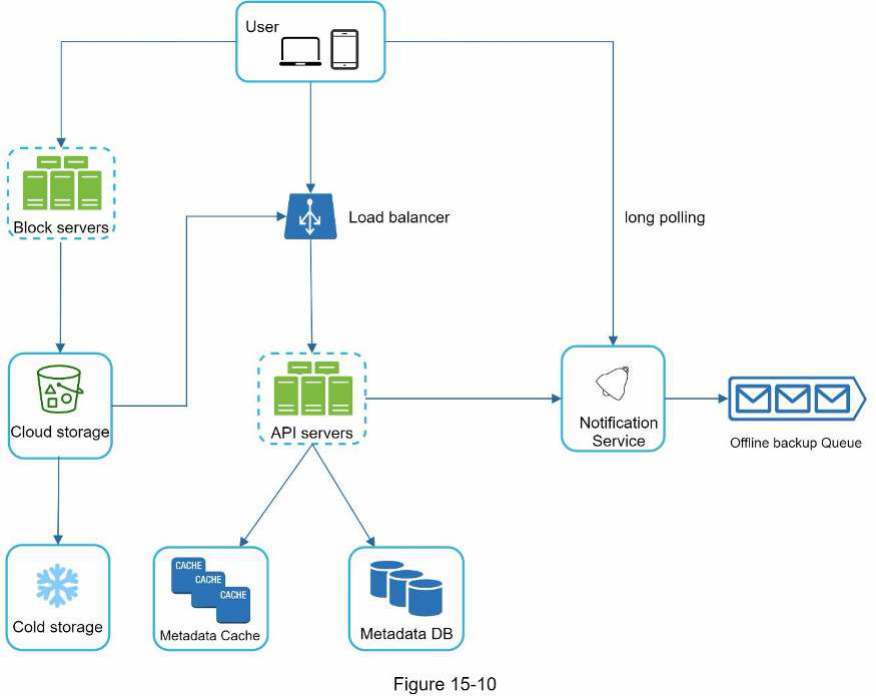
Người dùng: Người dùng sử dụng ứng dụng thông qua trình duyệt hoặc ứng dụng di động.
Máy chủ khối (Block servers): Máy chủ khối tải các khối (blocks) lên lưu trữ đám mây (cloud storage). Lưu trữ khối (tiếng Anh: Block storage), còn được gọi là lưu trữ cấp khối (tiếng Anh: block-level storage), là một công nghệ để lưu trữ các tệp dữ liệu trên môi trường dựa trên đám mây. Một tệp có thể được chia thành nhiều khối, mỗi khối có một giá trị băm (hash value) duy nhất, được lưu trữ trong Metadata database của chúng ta. Mỗi khối được coi là một đối tượng độc lập và được lưu trữ trong hệ thống lưu trữ của chúng ta (S3). Để tái tạo một tệp, các khối được nối lại theo một thứ tự cụ thể. Về kích thước khối, chúng ta sử dụng Dropbox làm tham chiếu: nó đặt kích thước tối đa của một khối là 4MB [6].
Lưu trữ đám mây (Cloud storage): Một tệp được chia thành các khối nhỏ hơn và được lưu trữ trong lưu trữ đám mây.
Lưu trữ lạnh (Cold storage): Lưu trữ lạnh là một hệ thống máy tính được thiết kế để lưu trữ dữ liệu không hoạt động, nghĩa là các tệp không được truy cập trong một thời gian dài.
Load balancer: Một Load balancer phân phối yêu cầu đồng đều giữa các API servers.
API servers: Chúng chịu trách nhiệm cho hầu hết mọi thứ khác ngoài luồng tải lên. Các API servers đ�ược sử dụng để xác thực người dùng, quản lý hồ sơ người dùng, cập nhật metadata tệp, v.v.
Metadata database: Nó lưu trữ metadata của người dùng, tệp, khối, phiên bản, v.v. Xin lưu ý rằng các tệp được lưu trữ trên đám mây và Metadata database chỉ chứa metadata.
Metadata cache: Một số metadata được lưu vào bộ đệm (cache) để truy xuất nhanh.
Notification service: Đây là một hệ thống xuất bản/đăng ký (publisher/subscriber) cho phép dữ liệu được chuyển từ Notification service đến các máy khách khi các sự kiện nhất định xảy ra. Trong trường hợp cụ thể của chúng ta, Notification service thông báo cho các máy khách liên quan khi một tệp được thêm/chỉnh sửa/xóa ở nơi khác để chúng có thể kéo các thay đổi mới nhất.
Hàng đợi sao lưu ngoại tuyến (Offline backup queue): Nếu một máy khách ngoại tuyến và không thể kéo các thay đổi tệp mới nhất, hàng đợi sao lưu ngoại tuyến sẽ lưu trữ thông tin để các thay đổi sẽ được đồng bộ hóa khi máy khách trực tuyến.
Chúng ta đã thảo luận về thiết kế của Google Drive ở cấp cao. Một số thành phần phức tạp và đáng để xem xét kỹ lưỡng; chúng ta sẽ thảo luận chi tiết về chúng trong phần đi sâu vào thiết kế.
Bước 3 - Đi sâu vào thiết kế
Trong phần này, chúng ta sẽ xem xét kỹ lưỡng các vấn đề sau: máy chủ khối, Metadata database, luồng tải lên, luồng tải xuống, Notification service, tiết kiệm không gian lưu trữ và xử lý lỗi.
Máy chủ khối
Đối với các tệp lớn được cập nhật thường xuyên, việc gửi toàn bộ tệp trong mỗi lần cập nhật tiêu tốn rất nhiều băng thông. Hai tối ưu hóa được đề xuất để giảm thiểu lượng lưu lượng mạng được truyền đi:
-
Đồng bộ hóa Delta (tiếng Anh: Delta sync). Khi một tệp được sửa đổi, chỉ các khối đã sửa đổi được đồng bộ hóa thay vì toàn bộ tệp bằng cách sử dụng thuật toán đồng bộ hóa [7] [8].
-
Nén (Compression). Áp dụng nén lên các khối có thể giảm đáng kể kích thước dữ liệu. Do đó, các khối được nén bằng các thuật toán nén tùy thuộc vào loại tệp. Ví dụ, gzip và bzip2 được sử dụng để nén các tệp văn bản. Cần có các thuật toán nén khác nhau để nén hình ảnh và video.
Trong hệ thống của chúng ta, các máy chủ khối thực hiện công việc nặng nhọc cho việc tải tệp lên. Các máy chủ khối xử lý các tệp được truyền từ máy khách bằng cách chia một tệp thành các khối, nén từng khối và mã hóa chúng. Thay vì tải toàn bộ tệp lên hệ thống lưu trữ, chỉ các khối đã sửa đổi được chuyển đi.
Hình 15-11 cho thấy cách một máy chủ khối hoạt động khi một tệp mới được thêm vào.
-
Một tệp được chia thành các khối nhỏ hơn.
-
Mỗi kh��ối được nén bằng các thuật toán nén.
-
Để đảm bảo bảo mật, mỗi khối được mã hóa trước khi được gửi đến lưu trữ đám mây.
-
Các khối được tải lên lưu trữ đám mây.
Hình 15-12 minh họa đồng bộ hóa delta, nghĩa là chỉ các khối đã sửa đổi được chuyển đến lưu trữ đám mây. Các khối được đánh dấu "block 2" và "block 5" đại diện cho các khối đã thay đổi. Sử dụng đồng bộ hóa delta, chỉ hai khối đó được tải lên lưu trữ đám mây.
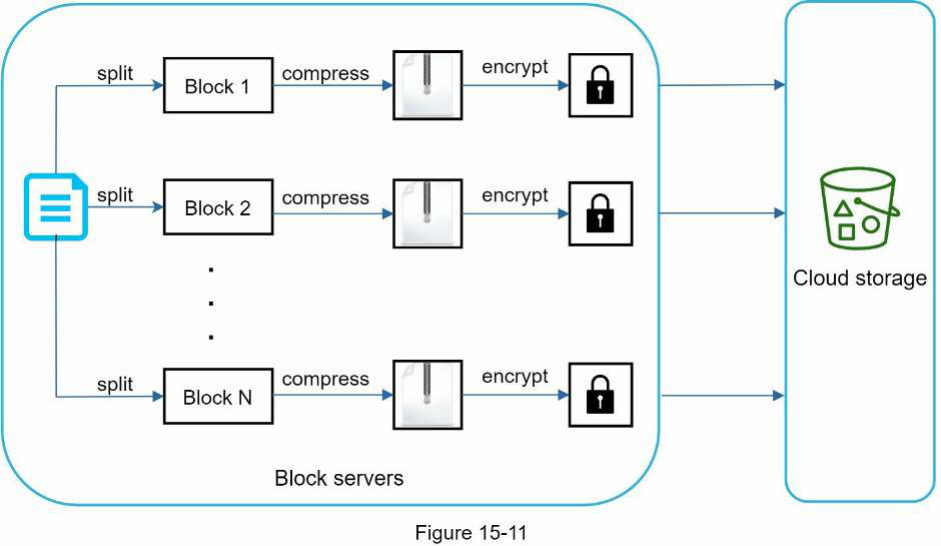
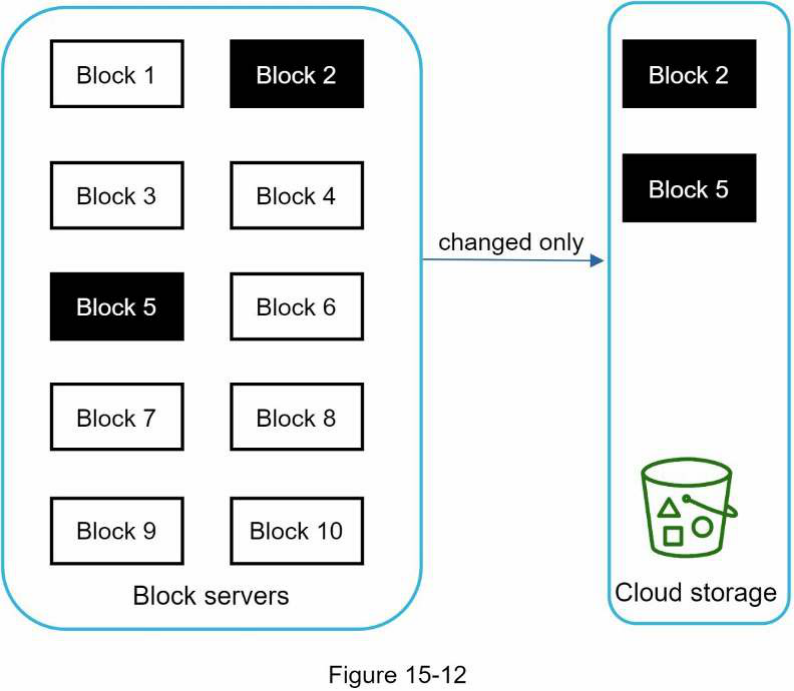
Các máy chủ khối cho phép chúng ta tiết kiệm lưu lượng mạng bằng cách cung cấp đồng bộ hóa delta và nén.
...được chuyển đến bộ nhớ đám mây (cloud storage). Các khối được tô sáng "block 2" và "block 5" đại diện cho các khối đã thay đổi. Sử dụng delta sync, chỉ hai khối đó được tải lên bộ nhớ đám mây.
Block server cho phép chúng ta tiết kiệm lưu lượng mạng bằng cách cung cấp delta sync và nén.
Yêu cầu nhất quán cao
Hệ thống của chúng ta yêu cầu tính nhất quán mạnh (strong consistency) theo mặc định. Việc một tệp được hiển thị khác nhau bởi các client khác nhau cùng một lúc là không thể chấp nhận được. Hệ thống cần cung cấp tính nhất quán mạnh cho các lớp cache metadata và cơ sở dữ liệu.
Các bộ nhớ đệm (memory cache) áp dụng mô hình nhất quán cuối cùng (eventual consistency) theo mặc định, điều này có nghĩa là các bản sao (replica) khác nhau có thể có dữ liệu khác nhau. Để đạt được tính nhất quán mạnh, chúng ta phải đảm bảo những điều sau:
-
Dữ liệu trong các bản sao cache và master là nhất quán.
-
Vô hiệu hóa cache khi ghi vào cơ sở dữ liệu để đảm bảo cache và cơ sở dữ liệu giữ cùng một giá trị. Đạt được tính nhất quán mạnh trong cơ sở dữ liệu quan hệ (relational database) rất dễ dàng vì nó duy trì các thuộc tính ACID (Atomicity, Consistency, Isolation, Durability) [9]. Tuy nhiên, các cơ sở dữ liệu NoSQL không hỗ trợ các thuộc tính ACID theo mặc định. Các thuộc tính ACID phải được tích hợp một cách lập trình vào logic đồng bộ hóa. Trong thiết kế của chúng ta, chúng ta chọn cơ sở dữ liệu quan hệ vì ACID được hỗ trợ nguyên bản.
Cơ sở dữ liệu metadata
Hình 15-13 cho thấy thiết kế lược đồ cơ sở dữ liệu (database schema). Xin lưu ý đây là một phiên bản được đơn giản hóa cao vì nó chỉ bao gồm các bảng quan trọng nhất và các trường (field) thú vị.
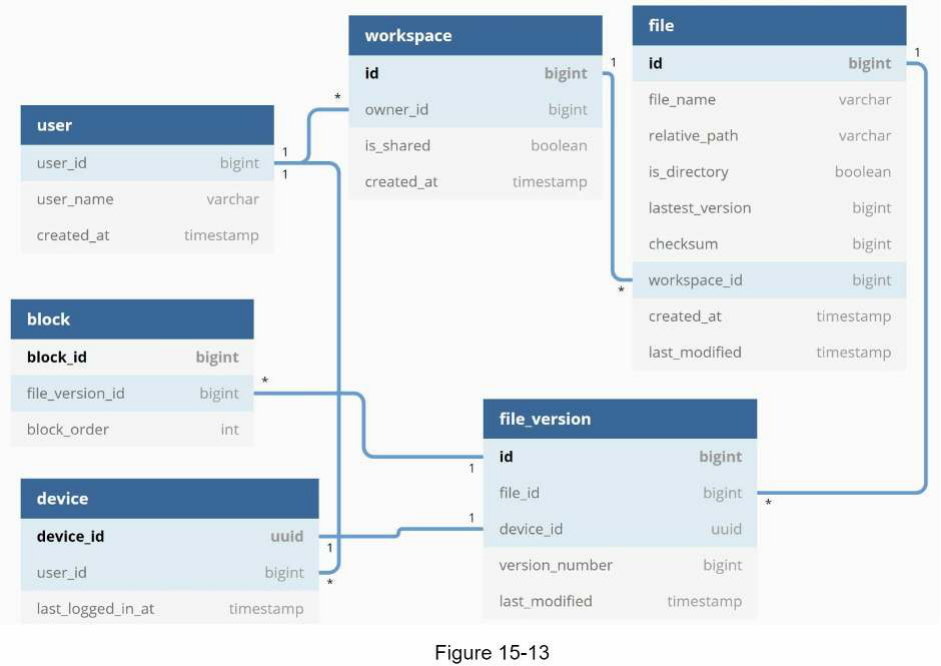
User : Bảng user chứa thông tin cơ bản về người dùng như tên người dùng (username), email, ảnh hồ sơ (profile photo), v.v.
Device : Bảng device lưu trữ thông tin thiết bị. Push_id được sử dụng để gửi và nhận thông báo đẩy (push notifications) trên thiết bị di động. Xin lưu ý rằng một người dùng có thể có nhiều thiết bị.
Namespace : Một namespace là thư mục gốc của một người dùng.
File: Bảng file lưu trữ mọi thứ liên quan đến tệp mới nhất.
File_version : Bảng này lưu trữ lịch sử phiên bản của một tệp. Các hàng (row) hiện có là chỉ đọc (read-only) để duy trì tính toàn vẹn của lịch sử sửa đổi tệp.
Block : Bảng này lưu trữ mọi thứ liên quan đến một block tệp. Một tệp ở bất kỳ phiên bản nào cũng có thể được tái tạo bằng cách nối tất cả các block theo đúng thứ tự.
Luồng tải lên (Upload flow)
Hãy cùng thảo luận điều gì xảy ra khi một client tải lên một tệp. Để hiểu rõ hơn về luồng này, chúng ta vẽ sơ đồ trình tự (sequence diagram) như trong Hình 15-14.
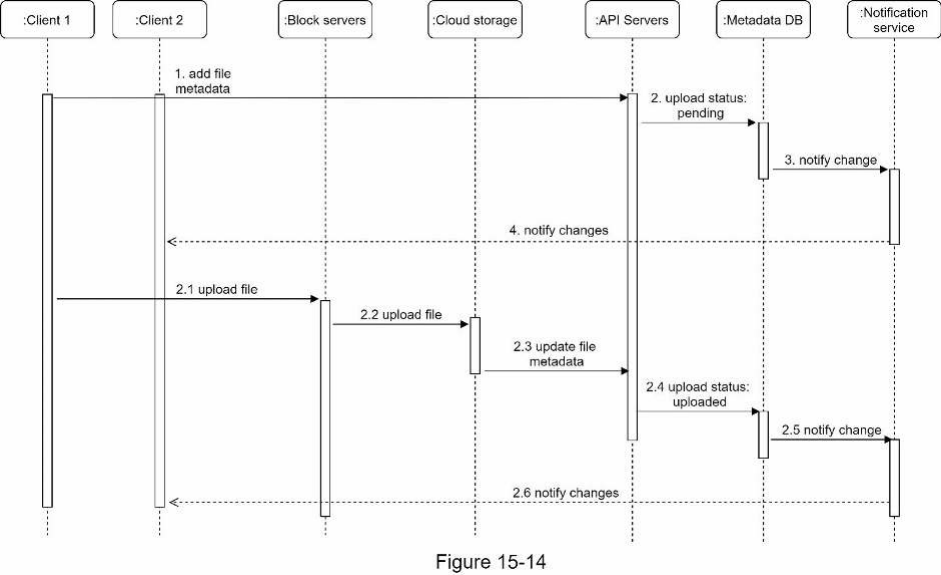
Trong Hình 15-14, hai yêu cầu được gửi song song: thêm metadata tệp và tải tệp lên bộ nhớ đám mây. Cả hai yêu cầu đều bắt nguồn từ client 1.
- Thêm metadata tệp.
- Client 1 gửi yêu cầu thêm metadata của tệp mới.
- Lưu metadata tệp mới vào Metadata DB và thay đổi trạng thái tải lên tệp thành “pending” (đang chờ xử lý).
- Thông báo cho notification service rằng một tệp mới đang được thêm vào.
- Notification service thông báo cho các client liên quan (client 2) rằng một tệp đang được tải lên.
- Tải tệp lên bộ nhớ đám mây. 2.1 Client 1 tải nội dung của tệp lên block server. 2.2 Block server chia tệp thành các block, nén, mã hóa các block và tải chúng lên bộ nhớ đám mây. 2.3 Sau khi tệp được tải lên, bộ nhớ đám mây kích hoạt callback hoàn tất tải lên (upload completion callback). Yêu cầu được gửi đến API server. 2.4 Trạng thái tệp được thay đổi thành “uploaded” (đã tải lên) trong Metadata DB. 2.5 Thông báo cho notification service rằng trạng thái tệp đã được thay đổi thành “uploaded.” 2.6 Notification service thông báo cho các client liên quan (client 2) rằng tệp đã được tải lên hoàn tất. Khi một tệp được chỉnh sửa, luồng tương tự, vì vậy chúng ta sẽ không lặp lại.
Luồng tải xuống (Download flow)
Luồng tải xuống được kích hoạt khi một tệp được thêm hoặc chỉnh sửa ở nơi khác. Làm thế nào để một client biết liệu một tệp đã được thêm hoặc chỉnh sửa bởi một client khác? Có hai cách để một client có thể biết:
-
Nếu client A đang trực tuyến (online) trong khi một tệp được thay đổi bởi một client khác, notification service sẽ thông báo cho client A rằng đã có thay đổi ở đâu đó nên nó cần kéo dữ liệu mới nhất.
-
Nếu client A đang ngoại tuyến (offline) trong khi một tệp được thay đổi bởi một client khác, dữ liệu sẽ được lưu vào cache. Khi client ngoại tuyến trực tuyến trở lại, nó sẽ kéo các thay đổi mới nhất.
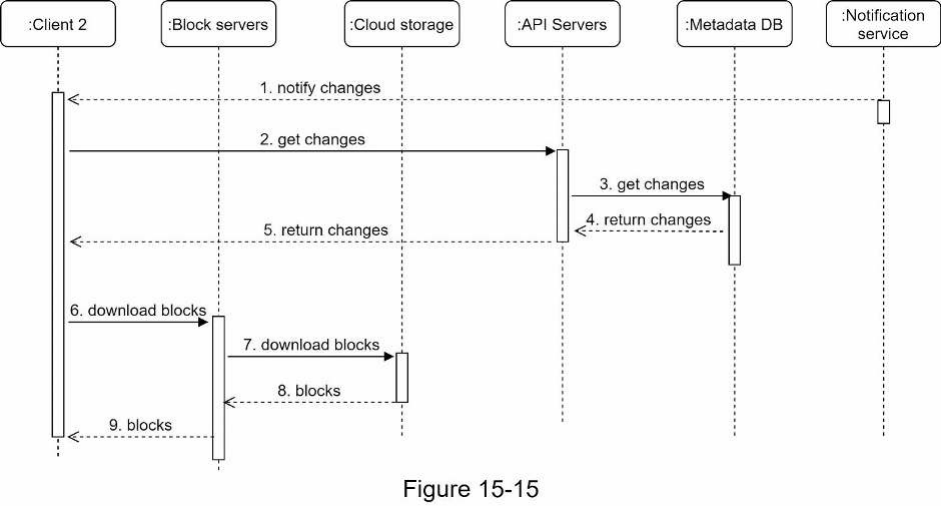
Khi một client biết một tệp đã thay đổi, trước tiên nó yêu cầu metadata thông qua API server, sau đó tải xuống các block để xây dựng lại tệp. Hình 15-15 cho thấy luồng chi tiết. Lưu ý, chỉ các thành phần quan trọng nhất được hiển thị trong sơ đồ do hạn chế về không gian.
- Notification service thông báo cho client 2 rằng một tệp đã được thay đổi ở nơi khác.
- Khi client 2 biết rằng có các bản cập nhật mới, nó sẽ gửi yêu cầu để lấy metadata.
- API server gọi Metadata DB để lấy metadata của các thay đổi.
- Metadata được trả về cho API server.
- Client 2 nhận metadata.
- Khi client nhận được metadata, nó gửi yêu cầu đến block server để tải xuống các block.
- Block server trước tiên tải xuống các block từ bộ nhớ đám mây.
- Bộ nhớ đám mây trả về các block cho block server.
- Client 2 tải xuống tất cả các block mới để xây dựng lại tệp.
Notification service
Để duy trì tính nhất quán của tệp, bất kỳ sự thay đổi (mutation) nào đối với tệp được thực hiện cục bộ cần phải được thông báo cho các client khác để giảm xung đột. Notification service được xây dựng để phục vụ mục đích này. Ở cấp độ cao, notification service cho phép dữ liệu được chuyển đến các client khi các sự kiện xảy ra. Dưới đây là một vài lựa chọn:
-
Long polling. Dropbox sử dụng long polling [10].
-
WebSocket. WebSocket cung cấp một kết nối liên tục giữa client và server. Giao tiếp là hai chiều (bi-directional).
Mặc dù cả hai lựa chọn đều hoạt động tốt, chúng ta chọn long polling vì hai lý do sau:
-
Giao tiếp cho notification service không phải là hai chiều. Server gửi thông tin về các thay đổi tệp cho client, nhưng không phải ngược lại.
-
WebSocket phù hợp cho giao tiếp hai chiều thời gian thực (real-time bi-directional communication) như ứng dụng trò chuyện. Đối với
 Google Drive, các thông báo được gửi không thường xuyên và không có sự bùng nổ dữ liệu.
Google Drive, các thông báo được gửi không thường xuyên và không có sự bùng nổ dữ liệu.
Với long polling, mỗi client thiết lập một kết nối long poll đến notification service. Nếu phát hiện các thay đổi đối với một tệp, client sẽ đóng kết nối long poll. Việc đóng kết nối có nghĩa là client phải kết nối với metadata server để tải xuống các thay đổi mới nhất. Sau khi nhận được phản hồi hoặc đạt đến thời gian chờ kết nối (connection timeout), một client ngay lập tức gửi một yêu cầu mới để duy trì kết nối mở.
Tiết kiệm không gian lưu trữ
Để hỗ trợ lịch sử phiên bản tệp và đảm bảo độ tin cậy, nhiều phiên bản của cùng một tệp được lưu trữ trên nhiều trung tâm dữ liệu (data center). Không gian lưu trữ có thể đầy nhanh chóng với việc sao lưu thường xuyên tất cả các bản sửa đổi tệp. Ba kỹ thuật được đề xuất để giảm chi phí lưu trữ:
-
Khử trùng lặp các block dữ liệu (De-duplicate data blocks). Loại bỏ các block dư thừa ở cấp độ tài khoản là một cách dễ dàng để tiết kiệm không gian. Hai block được coi là giống hệt nhau nếu chúng có cùng giá trị hash.
-
Áp dụng chiến lược sao lưu dữ liệu thông minh. Hai chiến lược tối ưu hóa có thể được áp dụng:
-
Đặt giới hạn: Chúng ta có thể đặt giới hạn cho số lượng phiên bản cần lưu trữ. Nếu đạt đến giới hạn, phiên bản cũ nhất sẽ được thay thế bằng phiên bản mới.
-
Chỉ giữ các phiên bản có giá trị: Một số tệp có thể được chỉnh sửa thường xuyên. Ví dụ, việc lưu mọi phiên bản đã chỉnh sửa cho một tài liệu được sửa đổi nhiều có thể có nghĩa là tệp được lưu hơn 1000 lần trong một khoảng thời gian ngắn. Để tránh các bản sao không cần thiết, chúng ta có thể giới hạn số lượng phiên bản đã lưu. Chúng ta ưu tiên hơn các phiên bản gần đây. Thử nghiệm rất hữu ích để tìm ra số lượng phiên bản tối ưu để lưu.
-
-
Di chuyển dữ liệu ít được sử dụng đến kho lưu trữ lạnh (cold storage). Dữ liệu lạnh là dữ liệu không hoạt động trong nhiều tháng hoặc nhiều năm. Kho lưu trữ lạnh như Amazon S3 Glacier [11] rẻ hơn nhiều so với S3.
[Context từ đoạn trước]: ...e more weight to recent versions. Experimentation is helpful to figure out the optimal number of versions to save.
- Moving infrequently used data to cold storage. Cold data is the data that has not been active for months or years. Cold storage like Amazon S3 glacier [11] is much cheaper than S3.
Xử lý sự cố
Trong một hệ thống quy mô lớn, các sự cố có thể xảy ra và chúng ta phải áp dụng các chiến lược thiết kế để giải quyết chúng. Người phỏng vấn có thể muốn nghe về cách chúng ta xử lý các sự cố hệ thống sau:
-
Sự cố Load balancer: Nếu một Load balancer gặp sự cố, Load balancer thứ cấp sẽ trở nên hoạt động và tiếp nhận lưu lượng truy cập. Các Load balancer thường giám sát lẫn nhau bằng cách sử dụng heartbeat (tín hiệu nhịp tim), một tín hiệu định kỳ được gửi giữa các Load balancer. Một Load balancer được coi là đã gặp sự cố nếu nó không gửi heartbeat trong một khoảng thời gian nhất định.
-
Sự cố máy chủ khối (block server): Nếu một máy chủ khối gặp sự cố, các máy chủ khác sẽ tiếp quản các công việc chưa hoàn thành hoặc đang chờ xử lý.
-
Sự cố lưu trữ đám mây: Các S3 bucket được sao chép nhiều lần ở các khu vực khác nhau. Nếu các tệp không có sẵn ở một khu vực, chúng có thể được lấy từ các khu vực khác.
-
Sự cố máy chủ API: Đây là một dịch vụ phi trạng thái (stateless). Nếu một máy chủ API gặp sự cố, lưu lượng truy cập sẽ được Load balancer chuyển hướng đến các máy chủ API khác.
-
Sự cố bộ nhớ đệm metadata: Các máy chủ bộ nhớ đệm metadata được sao chép nhiều lần. Nếu một node gặp sự cố, chúng ta vẫn có thể truy cập các node khác để lấy dữ liệu. Chúng ta sẽ khởi tạo một máy chủ bộ nhớ đệm mới để thay thế máy chủ bị lỗi.
-
Sự cố cơ sở dữ liệu metadata.
-
Master gặp sự cố: Nếu master gặp sự cố, hãy thăng cấp một trong các slave lên làm master mới và khởi tạo một node slave mới.
-
Slave gặp sự cố: Nếu một slave gặp sự cố, chúng ta có thể sử dụng một slave khác cho các hoạt động đọc và khởi tạo một máy chủ cơ sở dữ liệu khác để thay thế máy chủ bị lỗi.
-
-
Sự cố dịch vụ thông báo: Mỗi người dùng trực tuyến duy trì một kết nối long poll với máy chủ thông báo. Do đó, mỗi máy chủ thông báo được kết nối với nhiều người dùng. Theo bài nói chuyện của Dropbox vào năm 2012 [6], có hơn 1 triệu kết nối được mở trên mỗi máy. Nếu một máy chủ gặp sự cố, tất cả các kết nối long poll sẽ bị mất, vì vậy các client phải kết nối lại với một máy chủ khác. Mặc dù một máy chủ có thể duy trì nhiều kết nối mở, nhưng nó không thể kết nối lại tất cả các kết nối bị mất cùng một lúc. Việc kết nối lại với tất cả các client bị mất là một quá trình tương đối chậm.
-
Sự cố hàng đợi sao lưu ngoại tuyến: Các hàng đợi được sao chép nhiều lần. Nếu một hàng đợi gặp sự cố, các consumer của hàng đợi có thể cần đăng ký lại với hàng đợi sao lưu.
Bước 4 - Tổng kết
Trong chương này, chúng ta đã đề xuất một thiết kế hệ thống để hỗ trợ Google Drive. Sự kết hợp giữa tính nhất quán mạnh (strong consistency), băng thông mạng thấp và đồng bộ nhanh đã làm cho thiết kế này trở nên thú vị. Thiết kế của chúng ta bao gồm hai luồng: quản lý metadata tệp và đồng bộ tệp. Dịch vụ thông báo là một thành phần quan trọng khác của hệ thống. Nó sử dụng long polling để giữ cho các client được cập nhật với những thay đổi của tệp.
Giống như bất kỳ câu hỏi phỏng vấn thiết kế hệ thống nào, không có giải pháp nào là hoàn hảo. Mỗi công ty đều có những ràng buộc riêng và chúng ta phải thiết kế một hệ thống phù hợp với những ràng buộc đó. Việc nắm rõ các đánh đổi (tradeoffs) trong thiết kế và lựa chọn công nghệ của chúng ta là rất quan trọng. Nếu còn vài phút, chúng ta có thể nói về các lựa chọn thiết kế khác nhau.
Ví dụ, chúng ta có thể tải tệp trực tiếp lên lưu trữ đám mây từ client thay vì thông qua các máy chủ khối. Ưu điểm của cách tiếp cận này là nó giúp tải tệp lên nhanh hơn vì một tệp chỉ cần được chuyển một lần đến lưu trữ đám mây. Trong thiết kế của chúng ta, một tệp được chuyển đến các máy chủ khối trước, sau đó mới đến lưu trữ đám mây. Tuy nhiên, cách tiếp cận mới này có một vài nhược điểm:
-
Thứ nhất, cùng một logic phân đoạn (chunking), nén và mã hóa phải được triển khai trên các nền tảng khác nhau (iOS, Android, Web). Điều này dễ gây lỗi và đòi hỏi nhiều nỗ lực kỹ thuật. Trong thiết kế của chúng ta, tất cả các logic đó được triển khai ở một nơi tập trung: các máy chủ khối.
-
Thứ hai, vì client có thể dễ dàng bị tấn công hoặc thao túng, việc triển khai logic mã hóa ở phía client là không lý tưởng.
Một sự phát triển thú vị khác của hệ thống là chuyển logic trực tuyến/ngoại tuyến sang một dịch vụ riêng biệt. Chúng ta hãy gọi đó là dịch vụ hiện diện (presence service). Bằng cách chuyển dịch vụ hiện diện ra khỏi các máy chủ thông báo, chức năng trực tuyến/ngoại tuyến có thể dễ dàng được tích hợp bởi các dịch vụ khác.
Chúc mừng bạn đã đi được đến đây! Bây giờ hãy tự thưởng cho mình một lời khen. Làm tốt lắm!
Tài liệu tham khảo
[1] Google Drive: https://www.google.com/drive/
[2] Upload file data: https://developers.google.com/drive/api/v2/manage-uploads
[3] Amazon S3: https://aws.amazon.com/s3
[4] Differential Synchronization https://neil.fraser.name/writing/sync/
[5] Differential Synchronization youtube talk https://www.youtube.com/watch? v=S2Hp_1jqpY8
[6] How We’ve Scaled Dropbox: https://youtu.be/PE4gwstWhmc
[7] Tridgell, A., & Mackerras, P. (1996). The rsync algorithm.
[8] Librsync. (n.d.). Retrieved April 18, 2015, from https://github.com/librsync/librsync
[9] ACID: https://en.wikipedia.org/wiki/ACID
[10] Dropbox security white paper: https://www.dropbox.com/static/business/resources/Security_Whitepaper.pdf
[11] Amazon S3 Glacier: https://aws.amazon.com/glacier/faqs/
Made by Anh Tu - Share to be share